
SQL
INFO
还是得系统学学
数据库体系
- 连接层(Connection Layer):负责管理客户端与数据库服务器之间的连接,处理连接请求、认证和会话管理。
- 服务层(Service Layer):处理SQL解析、查询优化和执行计划生成等任务。
- 存储引擎层(Storage Engine Layer):负责实际的数据存储和检索,不同的存储引擎提供不同的存储机制和特性。
- 存储层(Storage Layer):负责物理数据存储,包括文件系统管理和数据页的读写操作。
存储引擎
- InnoDB
常用的引擎,也是MySQL默认的引擎。有事务支持,支持行级锁,适合高并发的场景。存储文件采用聚簇索引,数据和索引存储在一起,查询效率较高。使用.ibd文件存储表数据和索引信息,可以使用ibd2sdi工具将.ibd文件转换为SQL语句以便恢复数据。
- MyISAM
MySQL早期的默认引擎,后被InnoDB取代。适合读多写少的场景,即读和插入很多,但是更新和删除操作很少。使用表级锁,可能导致并发性能较差。存储文件采用非聚簇索引,数据和索引分开存储。使用.sdi存储表结构信息,使用.MYD文件存储表数据,.MYI文件存储索引信息。
实际上这个被mangodb替代了,因为mangodb的读写性能更好,而且支持更复杂的数据结构。
- MEMORY
将数据存储在内存中,适合需要快速访问数据的场景,但数据在服务器重启后会丢失。仅使用.sdi存储表结构信息,不存储数据文件。
实际上这个也被redis替代了,因为redis支持持久化存储,并且提供了丰富的数据结构和功能。
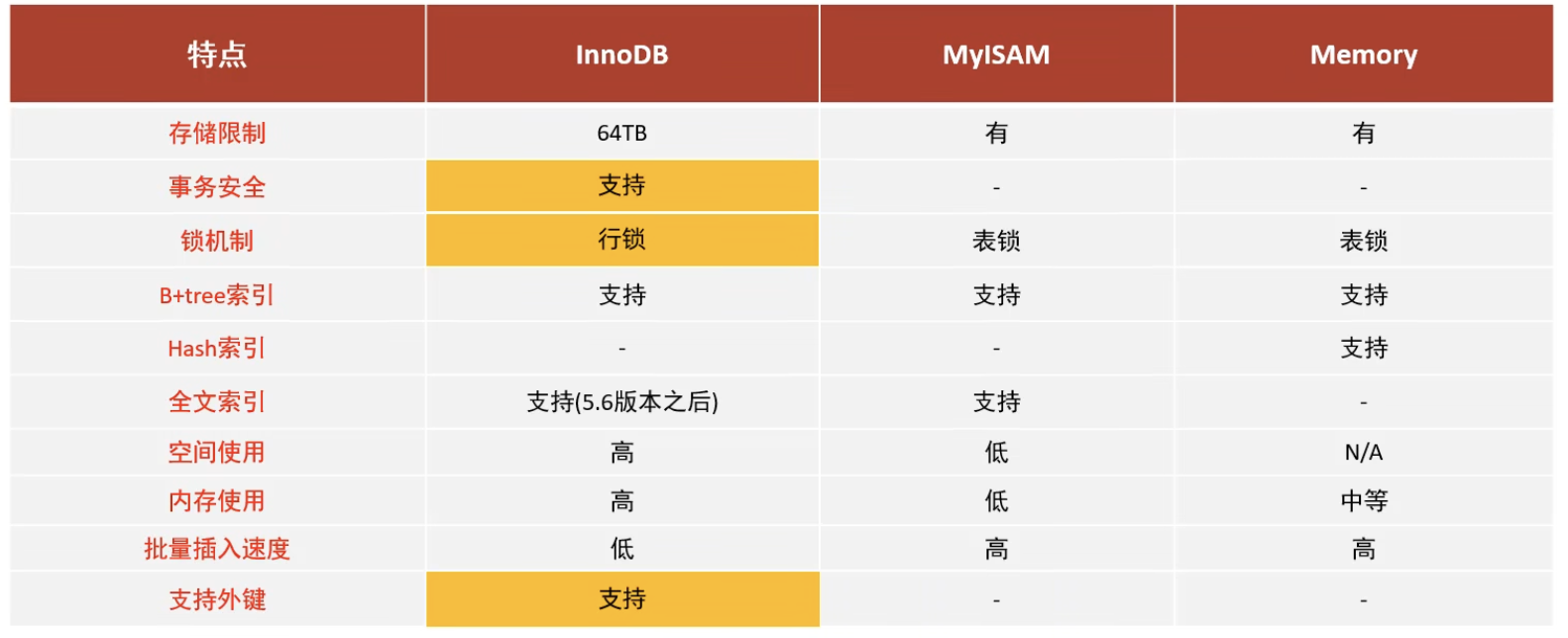
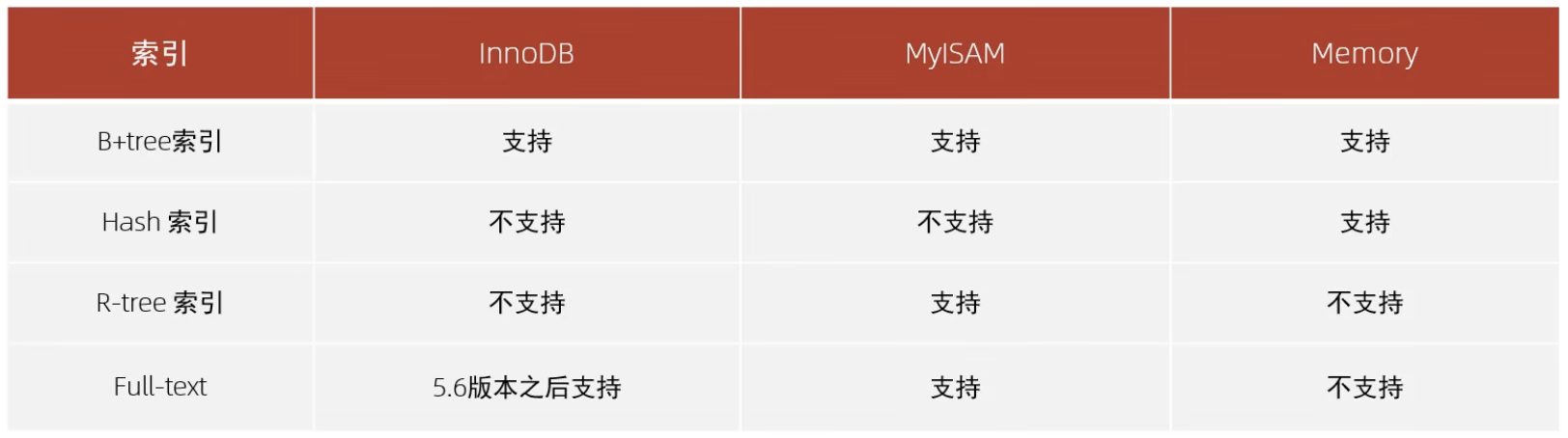
三大引擎对比
索引
是一种数据结构,用来高效获取数据。
优点
- 提高查询速度
- 减少磁盘I/O操作
- 支持排序和分组操作
缺点
- 占用存储空间
- 增加数据修改的开销
- 维护复杂性

B+树索引
- 支持等值查询和范围查询。
- 支持排序操作。
- 适用于大多数查询场景,效率较高。
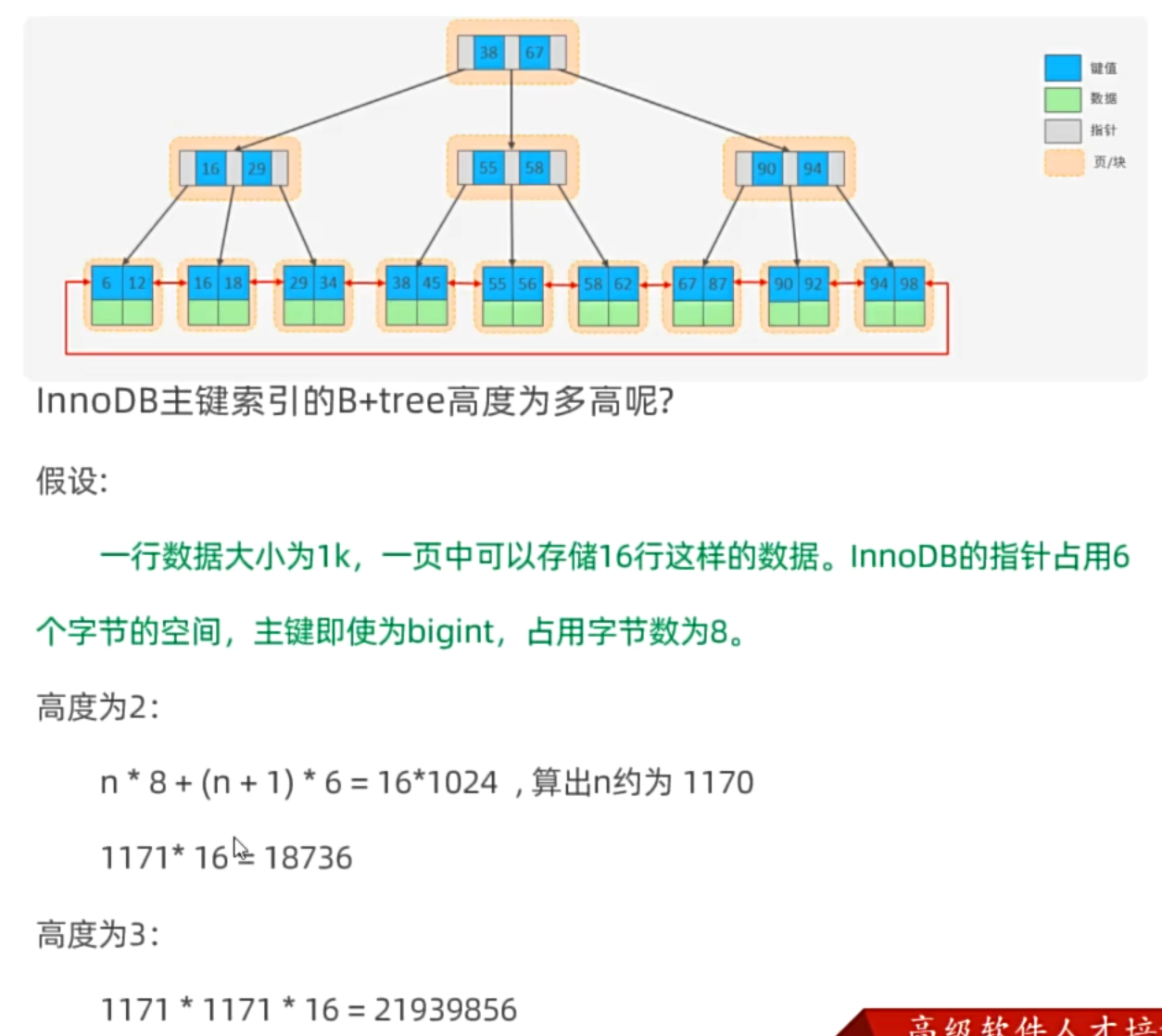
为什么用B+树作为索引结构?
二叉树的每个节点最多只有两个子节点,导致树的高度较大,查询时需要遍历更多的节点,增加了I/O操作次数;在顺序插入的时候会退化成链表,效率低。
B树相较于每个节点可以有多个子节点,减少了树的高度,提高了查询效率。但是B树存储的时候数据和索引放在一起,在同一个块里面又要存索引又要存数据,导致每个节点存储的索引数量减少,树的高度增加,查询效率降低。换句话说,同样的空间存索引,每个块可以存放的索引就会变多,平均下来遍历的块就会变少,查询效率就会提高。
B+树查找效率稳定,且由于叶子结点之间通过指针相连,利于于范围查询和排序操作,因此B+树被广泛应用于数据库索引结构中。
hash索引
- 只能用于等值查询,不支持范围查询。
- 无法进行排序操作。
- 效率高,比B+树还高,适用于频繁的等值查询。
索引分类

在innoDB存储引擎中,索引可以分为以下两种:
- 聚簇索引,数据和索引存储在一起,索引结构的叶子节点包含了数据行。必须有,且只有一个
- 二级索引(非聚簇索引),数据和索引分开存储。可以存在多个
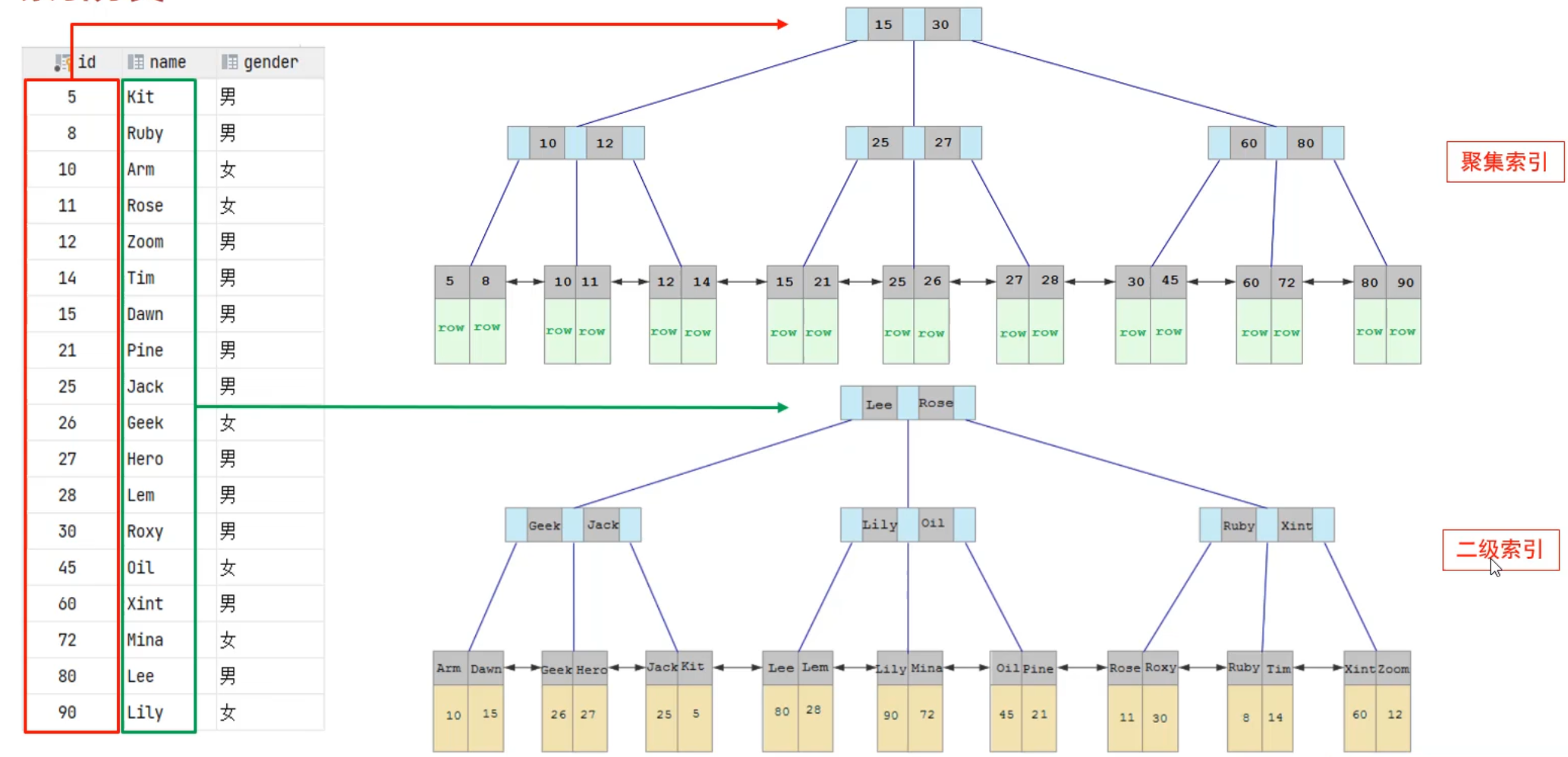 如图,如果使用二级查询,我们拿到的实际上是聚簇索引的键值,然后再去聚簇索引中查找对应的数据行。整个过程叫做回表查询。
如图,如果使用二级查询,我们拿到的实际上是聚簇索引的键值,然后再去聚簇索引中查找对应的数据行。整个过程叫做回表查询。
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引。
- 如果没有主键,但有唯一(非空)索引,唯一(非空)索引就是聚集索引。
- 如果没有主键和唯一(非空)索引,InnoDB会隐式创建一个行ID作为聚集索引。
索引 SQL
-- 创建常规索引(默认B+树)
CREATE INDEX index_name ON table_name (column1);
-- 创建唯一索引
CREATE UNIQUE INDEX index_name ON table_name (column1);
-- 创建联合索引
CREATE INDEX index_name ON table_name (column1, column2);
-- 删除索引
DROP INDEX index_name ON table_name;最左前缀法则
联合索引在查询时,只有当查询条件包含了索引的最左边的列,不能跳过索引中的列,才能有效利用该索引进行查询优化。这就是最左前缀法则。 例如,对于联合索引(A, B, C),以下查询可以利用该索引:
-- 利用索引
SELECT * FROM table_name WHERE A = 'value1';
SELECT * FROM table_name WHERE A = 'value1' AND B = 'value2';
SELECT * FROM table_name WHERE A = 'value1' AND B = 'value2' AND C = 'value3';而以下查询则不能利用该索引:
-- 不能利用索引
SELECT * FROM table_name WHERE B = 'value2';
SELECT * FROM table_name WHERE C = 'value3';
SELECT * FROM table_name WHERE A = 'value1' AND C = 'value3';范围查询与索引
在使用联合索引进行范围查询时,索引只能用于大于/小于号之前的列,范围查询之后的列将无法利用索引进行优化。但是可以将大于号改成大于等于号。
其他 索引失效
索引失效是指在某些情况下,数据库无法利用索引来优化查询,导致查询性能下降。常见的索引失效情况包括:
- 使用函数或表达式:在查询条件中对索引列使用函数或表达式会导致索引失效。sql
SELECT * FROM table_name WHERE LOWER(column1) = 'value'; - 隐式类型转换:当查询条件中的数据类型与索引列的数据类型不匹配时,会导致隐式类型转换,从而使索引失效。sql
SELECT * FROM table_name WHERE column1 = 123; -- column1是字符串类型 - 使用通配符:在LIKE查询中,如果通配符出现在字符串的开头,会导致索引失效。sql
SELECT * FROM table_name WHERE column1 LIKE '%value';
or连接情况
当查询条件中使用OR连接多个条件时,如果这些条件涉及不同的列,若任意一列没有索引,则索引失效。为了避免这种情况,可以考虑以下方法:
- 使用UNION替代OR:将OR条件拆分为多个查询,然后使用UNION将结果合并。sql
SELECT * FROM table_name WHERE column1 = 'value1' UNION SELECT * FROM table_name WHERE column2 = 'value2'; - 使用IN替代OR:如果OR条件涉及同一列的多个值,可以使用IN语句来替代。sql
SELECT * FROM table_name WHERE column1 IN ('value1', 'value2');
联合索引和or
当使用联合索引时,如果OR连接的条件涉及联合索引中的不同列,且这些列没有被最左前缀法则覆盖,则索引失效。直接点讲就是对于(a,b)联合索引,数据是先根据a排序的,如果or连接的条件是a=1 or b=2,那么b=2这个条件就无法利用索引,因为数据并不是根据b排序的。因此联合索引在这种情况下会失效。
但确实也存在一种特殊情况,对于最左前缀法则覆盖的列,联合索引仍然可以被利用。例如,对于(a,b)联合索引,查询条件是a=1 or a=2,这种情况下联合索引仍然有效,因为查询条件都涉及最左前缀列a。
特殊情况
当优化器判断使用索引的成本高于全表扫描时,索引会失效。例如,当查询返回大量数据时,优化器可能选择全表扫描而不是使用索引。
背后原理是因为使用索引会涉及额外的I/O操作,如查找索引节点和回表查询,而全表扫描则可以一次性读取所有数据页。当返回的数据量较大时,全表扫描的总I/O成本可能低于使用索引的成本。具体取决于数据分布、索引选择性和查询条件等因素。
指定/忽略使用索引
在某些情况下,优化器可能无法选择最佳的索引。可以使用FORCE INDEX强制使用指定的索引,或者使用IGNORE INDEX忽略某个索引。
-- 强制使用指定索引
SELECT * FROM table_name FORCE INDEX (index_name) WHERE column1 = 'value';
-- 忽略指定索引
SELECT * FROM table_name IGNORE INDEX (index_name) WHERE column1 = 'value';覆盖索引
覆盖索引是指查询所需的所有列都包含在索引中,无需回表查询即可获取结果。使用覆盖索引可以显著提高查询性能,因为避免了额外的I/O操作。尽量使用这个,减少使用select *。
-- 创建覆盖索引
CREATE INDEX idx_column1_column2 ON table_name (column1, column2);
-- 使用覆盖索引的查询
SELECT column1, column2 FROM table_name WHERE column1 = 'value';意思就是说,如果查询只涉及索引中的列,那么数据库可以直接从索引中获取数据,而不需要访问实际的数据行,从而提高查询效率。如果你想要额外的数据,就必须回表查询,等于多进行了一次流程。
前缀索引
对于字符串类型的列,可以创建前缀索引,只索引字符串的前N个字符,从而减少索引的存储空间和维护开销。前缀索引适用于前缀具有较高选择性的场景。
-- 创建前缀索引,索引前10个字符
CREATE INDEX idx_column1_prefix ON table_name (column1(10));索引选择性指不重复的索引值和数据表的记录总数的比值,选择性越高,索引的效果越好。唯一索引的选择性最高,选择性为1。
索引设计原则

SQL性能分析
查询执行频率
查询执行频率高的SQL语句,优化效果更明显。在MySQL中,可以使用SHOW [session|global] STATUS命令查看各类SQL语句的执行次数。
SHOW GLOBAL STATUS LIKE 'Com_%';执行后关注以下几个指标:
- Com_select:SELECT语句的执行次数
- Com_insert:INSERT语句的执行次数
- Com_update:UPDATE语句的执行次数
- Com_delete:DELETE语句的执行次数
慢查询日志
MySQL提供了慢查询日志功能,用于记录执行时间超过指定阈值的SQL语句。通过分析慢查询日志,可以找出性能瓶颈并进行优化。
可以在MySQL的配置文件/etc/my.cnf中通过以下命令启用慢查询日志:
# 启用慢查询日志
slow_query_log = 1
# 设置慢日志的时间阈值,单位为秒
long_query_time = 2启用后,慢查询日志通常存储在MySQL数据目录下的hostname-slow.log文件中。可以使用mysqldumpslow工具对慢查询日志进行汇总和分析。
profile
MySQL的SHOW PROFILE命令可以用来分析SQL语句的执行过程,帮助找出性能瓶颈。通过该命令,可以查看SQL语句在不同阶段的时间消耗情况。通过have_profiling参数,可以知道MySQL是否支持profile功能。
select @@have_profiling;如果返回值为YES,则表示支持profile功能。可以通过以下命令启用profile功能:
SET profiling = 1;启用后,执行SQL语句,然后使用SHOW PROFILES命令查看已执行的SQL语句及其对应的profile ID。
SHOW PROFILES;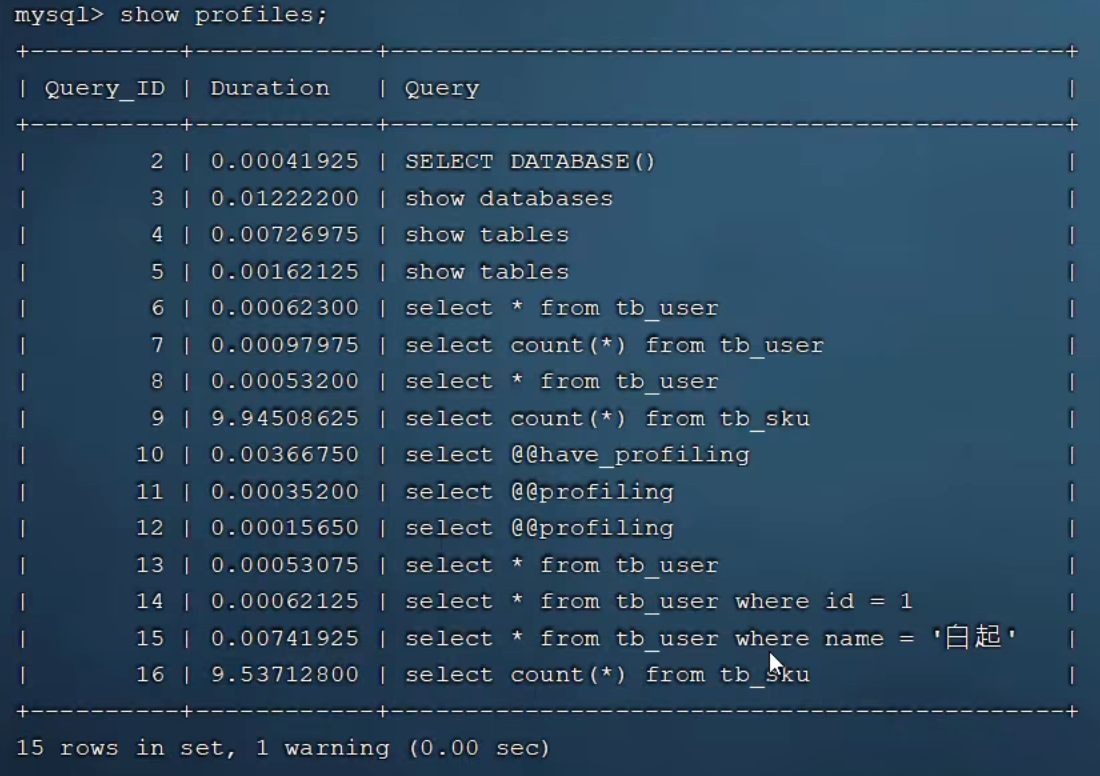
-- 查看指定profile ID的详细信息
SHOW PROFILE FOR QUERY query_id;
explain
EXPLAIN命令用于分析SQL语句的执行计划,帮助了解查询是如何被优化器处理的。通过EXPLAIN输出的信息,可以判断查询是否使用了索引、连接类型以及扫描的行数等,从而找出性能瓶颈并进行优化。
EXPLAIN SELECT * FROM table_name WHERE column1 = 'value';EXPLAIN输出的常见字段包括: 
索引对于SQL性能的提升非常显著。通过EXPLAIN分析,可以判断查询是否使用了索引,从而评估索引的有效性。
SQL优化
插入数据
- 批量插入数据比单条插入更高效。可以使用多值插入语法,一次性插入多条记录,减少网络往返次数和事务开销。
INSERT INTO table_name (column1, column2) VALUES
('value1a', 'value2a'),
('value1b', 'value2b'),
('value1c', 'value2c');- 在插入大量数据时,可以将多条插入操作放在一个事务中,减少事务提交的开销。
START TRANSACTION;
-- 执行多条插入操作
COMMIT;- 建议主键顺序插入,避免随机插入导致页分裂和碎片化。
- 在插入大批量数据时,使用insert性能低,可以使用load data infile语句,直接从文件导入数据,效率更高。
主键优化
在innoDB存储引擎中,表数据都是根据主键顺序组织存放的。这种存储方式的表称为索引组织表(IOT).
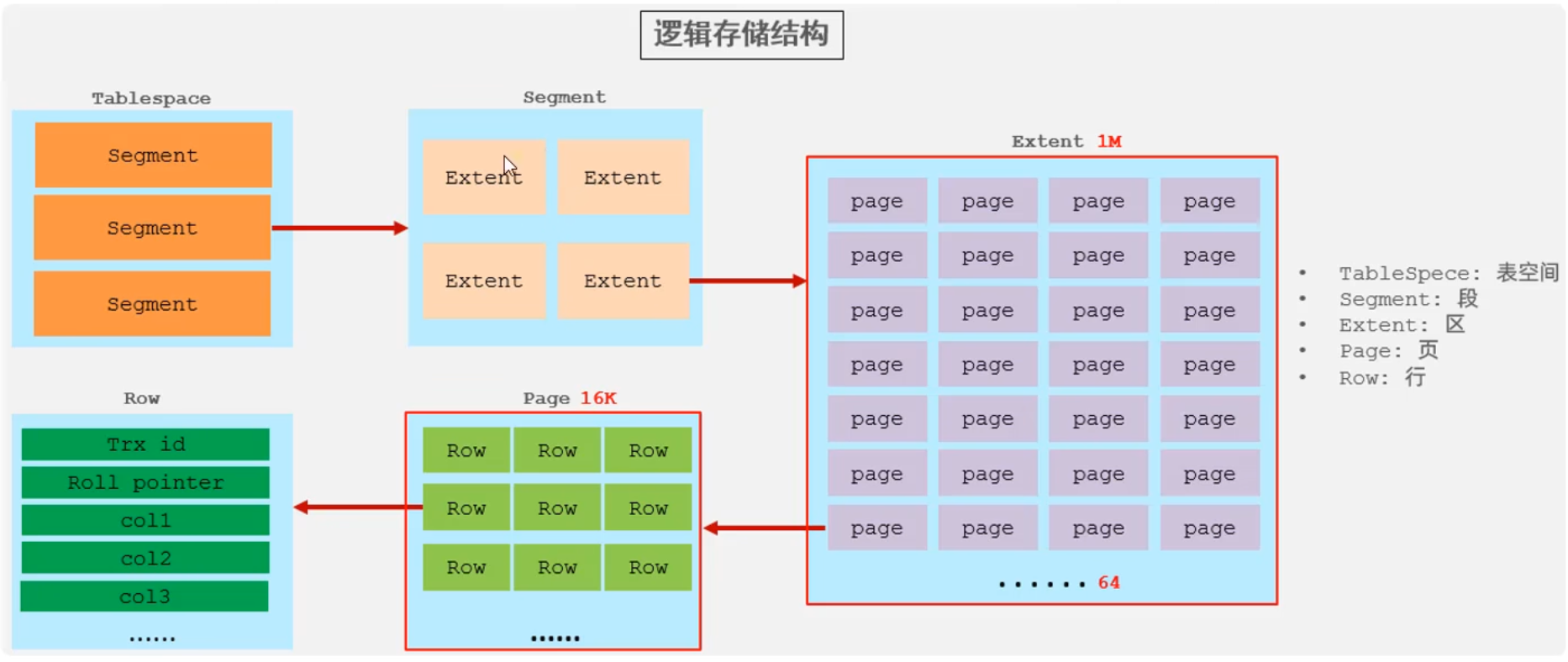 页可以为空,也可以填充一半。每个页包含2K到16K的数据,默认是16K,根据主键排列。页之间通过双向指针连接形成链表,便于顺序扫描和范围查询。
页可以为空,也可以填充一半。每个页包含2K到16K的数据,默认是16K,根据主键排列。页之间通过双向指针连接形成链表,便于顺序扫描和范围查询。
主键设计原则
- 满足业务需求的情况下,尽量降低主键的长度。
- 插入数据时,尽量顺序插入,使用AUTO_INCREMENT或UUIDv1等有序主键,避免随机插入导致页分裂和碎片化。
- 避免UUIDv4或是随机数作为主键,例如身份证号。
order by 优化
using filesort表示MySQL在执行ORDER BY操作时,无法利用索引进行排序,而是需要将结果集写入临时文件,然后再进行排序。这种方式通常比使用索引排序效率低,尤其是在处理大量数据时。using index表示MySQL在执行查询时,能够完全利用索引来获取所需的数据,而无需访问实际的表数据行。这通常发生在查询的所有列都包含在索引中时,即覆盖索引。
索引默认都是升序排列的,如果需要降序排列,可以在创建索引时指定DESC关键字。
CREATE INDEX idx_column1_desc ON table_name (column1 DESC);limit 优化
当使用LIMIT子句时,MySQL会先执行完整的查询,然后再从结果集中截取指定数量的记录。这种方式在处理大量数据时,可能导致性能问题。
对于limit 20000000000,10,MySQL需要扫描前20000000010条记录,然后返回最后的10条记录,效率非常低。优化方式为覆盖索引+子查询,具体操作如下:
-- 错误示范,in不支持limit
SELECT * FROM table_name WHERE id IN (
SELECT id FROM table_name ORDER BY id LIMIT 20000000000, 10
);
-- 可以用连表
-- 这里用到了覆盖索引,子查询只返回id列,避免了回表查询的开销,从而提高了查询效率。
SELECT t.* FROM table_name t, (SELECT id FROM table_name ORDER BY id LIMIT 20000000000, 10) a WHERE t.id = a.id;覆盖索引
覆盖索引是指查询所需的所有列都包含在索引中,无需回表查询即可获取结果。使用覆盖索引可以显著提高查询性能,因为避免了额外的I/O操作。尽量使用这个,减少使用select *。
count 优化
count计数方法由存储引擎决定,对InnoDB引擎来说就得一行一行读出来累计技术。
在MySQL中,COUNT(*)通常比COUNT(column_name)更高效,因为前者直接计算行数,而后者需要检查每一行的指定列是否为非NULL。
count用法:  其中
其中COUNT(1)和COUNT(*)在大多数情况下性能相似,都是计算行数。COUNT(column_name)会计算指定列中非NULL值的数量,可能稍微慢一些。
性能:count(字段) < count(主键id) < count(1) 约等于 count(*)
update优化
尽量根据主键/唯一索引进行更新,避免全表扫描导致性能问题。
-- 优化示例
UPDATE table_name SET column1 = 'value' WHERE id = 123; -- 使用主键索引视图
视图是基于SQL查询的虚拟表,可以简化复杂查询、提高代码复用性和安全性。视图本身不存储数据,而是每次查询时动态生成结果。
-- 创建/修改吗吗 视图
CREATE OR REPLACE VIEW view_name AS SELECT column1, column2 FROM table_name WHERE condition;
-- 查询视图
SELECT * FROM view_name;
-- 删除视图
DROP VIEW view_name;视图的作用
- 简化复杂查询:将复杂的SQL查询封装在视图中,用户可以像查询普通表一样查询视图,简化了查询操作。
- 提高代码复用性:视图可以被多个查询重用,避免了重复编写相同的SQL逻辑。
- 增强安全性:通过视图可以限制用户访问基础表的特定列或行,从而提高数据安全性。
检查选项
在创建视图时,可以使用WITH CHECK OPTION来确保通过视图进行的更新操作不会违反视图定义的条件。
CREATE OR REPLACE VIEW view_name AS SELECT column1, column2 FROM table_name WHERE condition;
CREATE OR REPLACE VIEW view_name2 AS SELECT column1, column2 FROM view_name WHERE condition2 WITH CASCADED CHECK OPTION;
CREATE OR REPLACE VIEW view_name3 AS SELECT column1, column2 FROM view_name WHERE condition3 WITH LOCAL CHECK OPTION;如上:
WITH CASCADED CHECK OPTION确保view_name2的更新操作必须满足view_name2和view_name的条件(这是默认选项)。WITH LOCAL CHECK OPTION确保view_name3的更新操作必须满足view_name3的条件,但不要求满足view_name的条件(因为condition后面没有跟着 WITH CHECK OPTION)。
视图更新
要使得视图可更新,视图中的行与基础表中的行之间必须存在一对一的关系。也就是说,视图中的每一行必须对应基础表中的唯一一行。这通常要求视图定义中包含基础表的主键或唯一索引列,并且视图中的查询不能包含聚合函数、DISTINCT、GROUP BY、HAVING等会导致结果集不唯一的操作。
-- 创建可更新的视图
CREATE OR REPLACE VIEW view_name AS SELECT id, column1 FROM table_name WHERE condition;在上述示例中,视图view_name包含了基础表table_name的主键列id,因此满足可更新视图的条件。通过这个视图进行的更新操作将直接影响基础表中的数据。
锁
按照锁的颗粒度划分,分为:
- 全局锁:锁定整个数据库,适用于需要对整个数据库进行维护的操作,如备份、恢复等。
- 表级锁:锁定整个表,适用于需要对整个表进行修改的操作,如ALTER TABLE等。
- 行级锁:锁定特定的行,适用于需要对表中的特定记录进行修改的操作,如UPDATE、DELETE等。
全局锁
全局锁是MySQL提供的一种特殊锁机制,用于在执行某些操作时锁定整个数据库实例,确保在锁定期间没有其他操作能够访问数据库。这种锁通常用于需要对整个数据库进行维护的操作,如备份、恢复等。
- 加锁:
FLUSH TABLES WITH READ LOCK;- 解锁:
UNLOCK TABLES;数据库加全局锁,是一个比较重的操作,存在以下问题:
- 如果在主库上备份,加全局锁会导致主库无法处理写请求,影响业务的正常运行。
- 如果在从库上备份,加全局锁会导致从库不能执行主库同步过来的二进制日志,导致主从数据不一致。
表级锁
表级锁是MySQL提供的一种锁机制,用于在执行某些操作时锁定整个表,确保在锁定期间没有其他操作能够访问该表。这种锁通常用于需要对整个表进行修改的操作,如ALTER TABLE等。
表级锁还分为三类:
- 表锁
- 元数据锁
- 意向锁
表锁
表锁分为表共享读锁和表独占写锁两种类型。表共享读锁允许多个事务同时读取表,但不允许任何事务修改表;表独占写锁则只允许一个事务读取或者修改表,并且在锁定期间不允许其他事务读取或修改表。
- 加锁:
LOCK TABLES table_name READ; -- 加共享读锁
LOCK TABLES table_name WRITE; -- 加独占写锁- 解锁:
UNLOCK TABLES;元数据锁
元数据即描绘数据的数据(表结构)。元数据锁(MDL)是系统自动控制的,无需显式调用,在访问一张表的时候会自动加上。其主要作用是维护表元数据的数据一致性,在表上有活动事务的时候,其他事务无法对该表进行DDL操作(如ALTER TABLE),以避免数据不一致的情况发生。
意向锁
意向锁是InnoDB存储引擎引入的一种锁机制,用于在表级别上表示事务对行级锁的意图。
意向锁分为两种类型:意向共享锁(IS)和意向排他锁(IX)。当一个事务需要对某行加共享锁时,会先在表上加一个IS锁;当一个事务需要对某行加排他锁时,会先在表上加一个IX锁。通过意向锁,InnoDB能够快速判断是否存在冲突的行级锁,使得表锁不用检查每行数据是否加锁,从而提高并发性能。
意向锁是mysql自动加的,不需要我们手动加锁。我们只需要在事务中对行加锁,mysql会自动在表上加上对应的意向锁。
意向锁之间不排斥,可以共存,也就是说一个表上面可以同时存在多个IS锁和IX锁。
| 当前表上的锁 \ 准备加的锁 | IS (意向共享锁) | IX (意向排他锁) | S (表级共享锁) | X (表级排他锁) |
|---|---|---|---|---|
| IS (意向共享锁) | ✅ 兼容 | ✅ 兼容 | ✅ 兼容 | ❌ 冲突 |
| IX (意向排他锁) | ✅ 兼容 | ✅ 兼容 | ❌ 冲突 | ❌ 冲突 |
| S (表级共享锁) | ✅ 兼容 | ❌ 冲突 | ✅ 兼容 | ❌ 冲突 |
| X (表级排他锁) | ❌ 冲突 | ❌ 冲突 | ❌ 冲突 | ❌ 冲突 |
行级锁
行级锁是MySQL提供的一种锁机制,用于在执行某些操作时锁定特定的行,确保在锁定期间没有其他操作能够访问该行。这种锁通常用于需要对表中的特定记录进行修改的操作,如UPDATE、DELETE等。行级锁可以提高并发性能,因为它允许多个事务同时访问同一表中的不同行,从而减少了锁竞争和等待时间。应用在InnoDB存储引擎中。
InnoDB的数据是基于索引组织的,行锁是通过对索引上的索引项加锁来实现的,而不是对记录加锁。当一个事务需要修改某行数据时,InnoDB会在该行数据所在的索引项上加上排他锁(X锁),其他事务如果需要访问该行数据,就必须等待该锁被释放。
行级锁也分为三类:
- 行锁:锁定单个行数据,适用于需要修改特定记录的操作,如UPDATE、DELETE等。在RC、RR隔离级别下都支持。
- 间隙锁:锁定索引记录之间的间隙,适用于需要防止其他事务插入特定范围内新记录的操作,如INSERT等。在RR隔离级别下支持。
- 临键锁:行锁和间隙锁的一个组合。锁定一个索引记录和它前面的间隙,适用于需要防止其他事务插入特定范围内新记录的操作,如INSERT等。在RR隔离级别下支持。
行锁
- 共享锁(S锁):允许多个事务同时读取同一行数据,但不允许任何事务修改该行数据。
- 排他锁(X锁):只允许一个事务读取或修改该行数据,并且在锁定期间不允许其他事务读取或修改该行数据。
间隙锁/临键锁(Next-Key Lock)
默认情况下,InnoDB在REPEATABLE READ事务隔离级别运行,InnoDB使用next-key锁(临键锁)进行搜索和索引扫描,以防止幻读。
注意:间隙锁的唯一目的是防止其他事务在锁定的范围内插入新记录,而不是锁定现有的记录。因此,间隙锁不会阻止其他事务修改或删除已经存在的记录。间隙锁可以共存,一个事务采用的间隙锁不会阻止另一个事务采用相同范围的间隙锁。
锁退化/优化规则:
- 索引上的等值查询(唯一索引),给不存在的记录加锁时,优化为间隙锁。
- 索引上的等值查询(普通索引),向右遍历时最后一个值不满足查询需求时,退化为间隙锁。
- 索引上的范围查询(唯一索引)-- 会访问到不满足条件的第一个值为止。
以上规则的讲解
Next-Key Lock(临键锁) = 间隙锁 + 记录锁 它锁住的是一个左开右闭的区间,比如 (10, 20]。
以上规则的根本目的是:在能防止幻读的前提下,尽量少锁一点数据,把门缝开大一点,让别的事务能多干点活(提高并发性能)。
我们假设有一张表,里面有三行数据:
- 唯一索引(比如主键 ID):10, 20, 30
- 普通索引(比如年龄 Age):10, 20, 30
- 对于规则1
- 你的操作:你想锁住 ID 为 15 的数据(WHERE id = 15 FOR UPDATE),这句话是代表我即将插入一条
id=15的数据,因此它不存在是正常的,但你不能让它在我插入之前被别人插入。但是表里只有 10 和 20,15 不存在。 - InnoDB 的内心戏:既然 ID 是唯一的,而且 15 现在不存在,那我只要防止别人在这个时候把 15 插进来就行了。
- 锁的退化:它本该锁住
(10, 20]。但它发现 20 这条记录跟你查的 15 没半毛钱关系,锁住 20 会影响别人修改 20。所以,它把 20 身上的记录锁去掉了,退化成了一个纯粹的间隙锁(10, 20)。 - 结果:别人不能插入 11~19,但是完全可以修改或删除 20。并发能力提升!
- 对于规则2
- 你的操作:你想锁住年龄为 20 的人(WHERE age = 20 FOR UPDATE)。
- InnoDB 的内心戏:因为年龄不是唯一的,表里可能有很多个 20。所以我找到第一个 20 后,必须继续往右边找,直到撞见第一个不是 20 的数据(也就是 30),我才能确定 20 已经全部找完了。
- 锁的退化:为了防止别人在 20 和 30 之间插入新的 20,它必须在这个区间加锁,本该加 Next-Key 锁 (20, 30]。但是,它看了一眼 30,心想:“人家是 30,根本不满足 age = 20 的条件,我凭什么锁人家?” 于是,它把 30 的记录锁去掉了,退化成了间隙锁 (20, 30)。
- 结果:别人不能在 20 到 30 之间插入新数据,但是可以自由修改 30 这条记录。并发能力再次提升!
- 对于规则3
- 你的操作:你要查一个范围(WHERE id > 10 AND id < 25 FOR UPDATE)。
- InnoDB 的内心戏:范围查询没法精准定位,我只能顺着藤摸瓜。我先找到 20,满足条件!继续往右找,撞到了 30。
- 执行逻辑:当它访问到 30 的时候,发现 30 < 25 这个条件不成立了,它就会立刻停止扫描。这句话其实是想告诉你,范围查询的“刹车片”在哪。它会把沿途扫过的地方都加上 Next-Key 锁,也就是锁住 (10, 20],然后为了封死边界,通常还会把 30 也卷进来锁住 (20, 30],防止别人在边界处搞事情。
死锁的可能性
对于规则一,如果两个事务同时执行 WHERE id = 15 FOR UPDATE,它们都会试图在 (10, 20) 这个区间上加一个间隙锁,此时禁止其他的事务在这个区间内插入数据。由于间隙锁之间是兼容的,所以它们都能成功加锁,但是他们都会尝试在这个区间内插入 id = 15 的数据,但由于互相之间的锁定,他们会互相等待对方释放锁,最终导致死锁。数据库会检测到这种情况,并会回滚其中一个事务以解决死锁问题。
MySQL可以检测到死锁,并会回滚其中一个事务来解决死锁问题。被回滚的事务会收到一个错误消息,提示发生了死锁。
事务
事务是数据库管理系统中的一个重要概念,指的是一组操作的集合,这些操作要么全部成功,要么全部失败。事务具有四个基本特性,通常被称为ACID特性:
- 原子性(Atomicity):事务中的所有操作要么全部成功,要么全部失败,不会出现部分成功的情况。
- 一致性(Consistency):事务执行前后,数据库都必须处于一致的状态。也就是说,事务必须使数据库从一个一致的状态转变到另一个一致的状态。
- 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应该影响其他事务的执行。不同的隔离级别定义了不同程度的隔离。
- 持久性(Durability):一旦事务提交成功,对数据库的修改应该是永久性的,即使系统发生故障也不会丢失。
事务原理
- 原子性/一致性/持久性:通过使用日志(如undo log和redo log)来实现事务的原子性、一致性和持久性。当一个事务开始时,数据库会记录该事务的操作日志,如果事务执行过程中发生错误,数据库可以通过日志回滚到事务开始之前的状态,确保原子性和一致性;如果事务成功提交,数据库会将修改记录到日志中,以确保持久性。
- 隔离性:通过使用锁(如行锁、表锁)和多版本并发控制(MVCC)来实现事务的隔离性。不同的隔离级别定义了不同程度的隔离,数据库会根据隔离级别来决定如何加锁和管理事务之间的并发访问。
事务隔离级别
| 隔离级别 (Isolation Level) | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) | 常见默认数据库 / 说明 |
|---|---|---|---|---|
| 1. 读未提交 (Read Uncommitted) | ❌ 可能发生 | ❌ 可能发生 | ❌ 可能发生 | 性能最高,但极度不安全,基本不用 |
| 2. 读已提交 (Read Committed) | ✅ 已解决 | ❌ 可能发生 | ❌ 可能发生 | Oracle, SQL Server 等数据库的默认级别 |
| 3. 可重复读 (Repeatable Read) | ✅ 已解决 | ✅ 已解决 | ❌ 可能发生* | MySQL (InnoDB) 的默认级别 |
| 4. 串行化 (Serializable) | ✅ 已解决 | ✅ 已解决 | ✅ 已解决 | 性能最差,事务排队串行执行,绝对安全 |
注:在 SQL 标准规范中,“可重复读”级别下依然允许发生幻读。但是,MySQL 的 InnoDB 引擎非常特殊,它在此级别下,通过结合 MVCC (多版本并发控制) ** 和 Next-Key 锁 (临键锁),在绝大多数场景下已经成功解决了幻读问题**。
三大读取异常
- 脏读 (Dirty Read):读到了其他事务未提交的修改数据。
- 不可重复读 (Non-Repeatable Read):同一次事务中,两次查询同一行数据,由于被他人修改或删除并提交,导致结果不一致。
- 幻读 (Phantom Read):同一次事务中,按相同条件进行范围查询,由于被他人插入了新行,导致查出的“记录条数”像幻影一样变多了。例如:你正在统计今天所有转账金额大于 5000 的交易记录,准备打印报表。你第一次查,查出来有 10 条记录。此时,另一个人突然往系统里插入了一笔 6000 的新交易并提交了。你为了确认,又执行了一次同样的查询,结果查出来 11 条记录。
redo log
redo log(重做日志)是InnoDB存储引擎用来保证事务持久性的一种机制。当一个事务提交时,InnoDB会将该事务的修改记录写入redo log中,以确保即使在系统崩溃的情况下,也能够通过redo log来恢复数据。
该日志文件由两部分组成:redo log buffer(重做日志缓冲区)和redo log file(重做日志文件)。
当事务提交时,InnoDB会将修改记录先写入redo log buffer(位于内存)中,然后再将其刷新到磁盘上的redo log file(位于磁盘)中。同步日志而不是直接同步数据的原因是:日志文件通常比数据文件小得多,写入日志的速度更快,可以显著提高事务提交的性能,这个称为WAL(Write-Ahead Logging)。
undo log
undo log(回滚日志)是InnoDB存储引擎用来实现事务原子性和一致性的一种机制。当一个事务执行修改操作时,InnoDB会将该操作的前镜像(即修改前的数据状态)记录在undo log中,以便在需要回滚事务时能够恢复数据。
undo log和redo log记录的内容不同,undo log记录的是修改前的数据状态,而redo log记录的是修改后的数据状态。undo log主要用于事务回滚和MVCC(多版本并发控制),而redo log主要用于事务提交和数据恢复。
当我们delete一条记录时,undo log会记录一条对应的insert记录;当我们update一条记录时,undo log会记录一条对应的update记录;当我们insert一条记录时,undo log会记录一条对应的delete记录。当执行rollback时,InnoDB会根据undo log中的记录来恢复数据到事务开始之前的状态。
- undo log销毁:当一个事务提交或回滚后,InnoDB会将该事务的undo log标记为可重用,并在适当的时候进行清理和销毁(不会立即删除,因为可能用于MVCC),以释放存储空间。
- undo log的存储:undo log通常存储在一个独立的表空间中,称为undo tablespace。这个表空间专门用于存储undo log,以便在需要回滚事务时能够快速访问和恢复数据。
物理日志和逻辑日志
- 物理日志:记录的是数据页的物理修改操作,例如:修改了哪个数据页的哪个位置,修改了多少字节等。这种日志通常比较底层,直接反映了数据的物理存储结构。redo log属于物理日志的一种。
- 逻辑日志:记录的是数据的逻辑修改操作,例如:修改了哪个表的哪个行,修改了哪些列等。这种日志更抽象,反映了数据的业务逻辑层面。undo log属于逻辑日志的一种。
MVCC
MVCC(Multi-Version Concurrency Control,多版本并发控制)是一种数据库并发控制机制,允许多个事务同时访问数据库而不会互相干扰。MVCC通过为每个事务维护数据的多个版本来实现这一点,从而提高了数据库的并发性能和响应速度。
MVCC 的伟大之处就在于它实现了:读写不等待,读不阻塞写,写不阻塞读。
基本概念
- 当前读
当前读是指事务读取最新提交的数据版本。当一个事务执行当前读时,它会看到其他事务已经提交的最新数据。对于我们日常的操作,比如:select ... lock in share mode, select ... for update, update, insert, delete等,都是当前读。
大白话就是:当前读就像看直播一样,事务看到的都是数据库的最新状态,任何时候都能看到最新的数据。且为了保证数据的一致性,当前读会加锁,阻止其他事务修改正在读取的数据。
- 快照读
快照读是指事务读取在其开始时刻已经存在的数据版本,有可能是历史数据,不加锁,是非阻塞读。当一个事务执行快照读时,它会看到一个一致性的快照,这个快照反映了事务开始时刻的数据状态。对于我们日常的操作,比如:简单的select等,都是快照读。
大白话就是:快照读就像拍了一张照片一样,事务开始时拍了一张数据库的照片,之后无论数据库怎么变,这个事务看到的都是这张照片里的数据。
- Read Committed: 每次select,都生成一个快照读。
- Repeatable Read: 事务开始时生成一个快照,整个事务期间都使用这个快照。
- Serializable: 快照读会退化为当前读。
读取事务
读取事务实际上也是在一个事务里运行的,如果读取了数据之后,事务没有提交,那么这个读取事务就一直存在,直到它提交或者回滚为止。这个读取事务的存在会导致一些问题,比如:如果有一个长时间运行的读取事务,它会持有一个旧的快照,这个快照可能会阻止undo log的清理,从而导致undo log文件不断增长,最终可能会耗尽磁盘空间。
除此之外,所有的 UPDATE 在动手修改前,都会偷偷先执行一次“当前读”,获取最新鲜的数据。
MVCC实现原理
MVCC的实现依赖于数据库记录中的三个隐藏字段,undo log日志以及readView。
隐藏字段
- db_trx_id:记录最后一次插入或修改该行数据的事务的唯一编号(全局递增)。
- db_roll_ptr:指向该行数据修改前的上一个历史版本(存放在 Undo Log 中)。
- DB_row_ID:隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段。
undo log
上面介绍过了,这里是拓展了。上面提到过undo log不会被立即删除,实际上在insert的时候可以立即删除,但是update和delete不行。
undo log版本链:当一行数据被多次修改时,undo log会形成一个版本链,每个版本都指向上一个版本。通过这个版本链,MVCC可以根据事务的快照来确定应该读取哪个版本的数据。
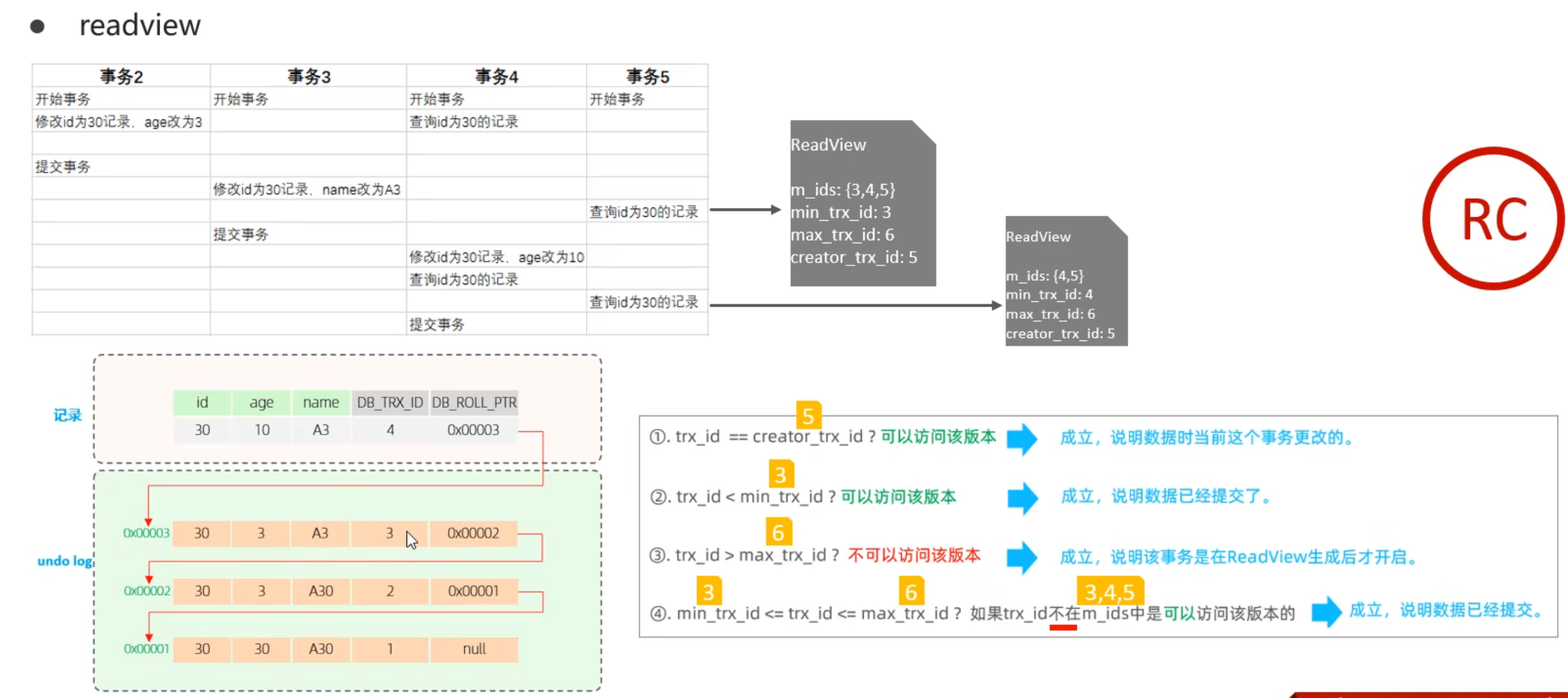
readView
readView是MVCC实现的一种机制,用于维护事务的快照。当一个事务开始时,InnoDB会创建一个readView对象,记录并维护系统当前活跃的事务(未提交的)id。
包含四个核心字段:
- m_ids: 活跃事务ID列表,记录当前系统中所有未提交的事务ID。
- min_trx_id: 活跃事务ID列表中的最小事务ID。
- max_trx_id: 即将分配的下一个事务ID,等于当前系统中最大的事务ID加1。
- creator_trx_id: 创建该readView的事务ID。
当事务顺着 Undo Log 版本链寻找数据时,会将数据版本上的 trx_id 与 Read View 进行对比。判断逻辑如下:
| 条件判断公式 | 结论 | 原理解释 |
|---|---|---|
trx_id == creator_trx_id | ✅ 可见 | 这条数据是当前事务自己修改的,当然能看到。 |
trx_id < min_trx_id | ✅ 可见 | 该版本在拍快照前,其所属事务早就已经提交了。 |
trx_id >= max_trx_id | ❌ 不可见 | 该版本是在拍快照之后,由未来的新事务生成的。 |
min_trx_id <= trx_id < max_trx_id | 需查 m_ids | 处于拍快照时的“并发时代”,需要进一步判断: 1. 若 trx_id 在 m_ids 数组中:说明生成该版本的事务还未提交,❌ 不可见。2. 若 trx_id 不在 m_ids 数组中:说明生成该版本的事务刚好已经提交,✅ 可见。 |
执行逻辑:从版本链的头部(最新数据)开始套用上述规则,如果判定为不可见,就顺着
roll_pointer找下一个老版本,直到找到第一个可见的版本为止。
对于不同的隔离级别,readView的使用方式也不同:
- Read Committed: 每次执行SELECT时,都会创建一个新的readView对象,确保每次读取的数据都是最新提交的。
- Repeatable Read: 仅在事务中第一次执行快照读时创建一个readView对象,后续复用这个readView,确保整个事务期间读取的数据版本一致。
RC隔离级别下的MVCC
再强调一遍,在Read Committed隔离级别下,每次执行SELECT时,都会创建一个新的readView对象,确保每次读取的数据都是最新提交的。这意味着,在Read Committed隔离级别下,事务每次执行快照读时,都会看到其他事务已经提交的最新数据版本,因此可能会发生不可重复读和幻读。
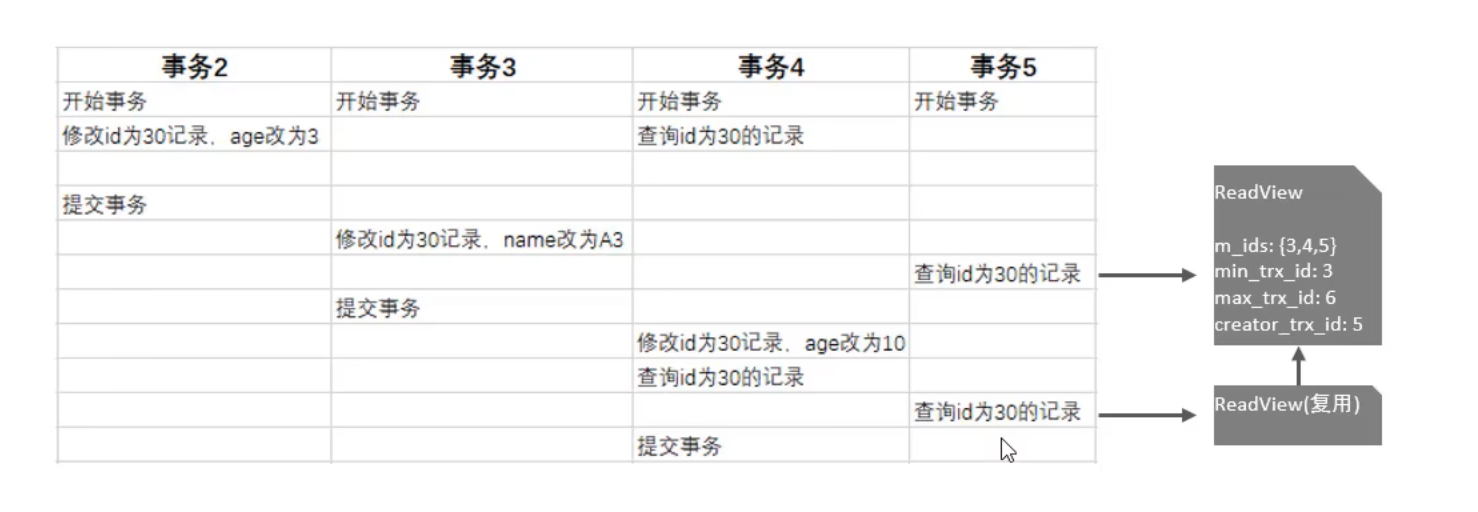
RR隔离级别下的MVCC
在Repeatable Read隔离级别下,事务在第一次执行快照读时创建一个readView对象,后续复用这个readView,确保整个事务期间读取的数据版本一致。这意味着,在Repeatable Read隔离级别下,事务在第一次执行快照读时看到的数据版本将一直保持不变,即使其他事务提交了新的数据版本,也不会影响当前事务的读取结果,从而避免了不可重复读的问题。
gemini生成的例子
- 初始场景设定
假设数据库中有一张账户表 account,目前里面有一行数据:张三,余额 1000。 这行数据是由过去一个老事务(事务 ID 为 50)插入的。
在 InnoDB 底层,这行数据实际上包含了我们看不见的隐藏字段:
trx_id= 50 (最后修改它的事务 ID)roll_pointer= null (目前没有更老的历史版本)
当前隔离级别:MySQL 默认的 RR(可重复读)。
- 并发操作时间线
现在,有三个事务同时出场,我们来看看时间线:
| 时间点 | 事务 A (trx_id=100) | 事务 B (trx_id=200) | 事务 C (trx_id=300) |
|---|---|---|---|
| T1 | BEGIN; 执行 SELECT 查询余额 | ||
| T2 | BEGIN; UPDATE 余额改为 2000 COMMIT; (已提交) | ||
| T3 | BEGIN; UPDATE 余额改为 3000 (注意:未提交) | ||
| T4 | 再次执行 SELECT 查询余额 |
- 底层原理深度推演
第一步:T1 时刻,生成 Read View (快照)
当事务 A 第一次执行 SELECT 时,MVCC 机制会被触发,为事务 A 生成一张专属于它的快照 (Read View)。 此时系统里只有事务 A 自己在运行,未来的 B 和 C 还没开启。
事务 A 的 Read View 核心属性如下:
m_ids(活跃事务列表) =[100]min_trx_id(最小活跃 ID) =100max_trx_id(下一个将要分配的 ID) =101creator_trx_id(自己) =100
此时事务 A 去读数据,看到数据的 trx_id = 50。
- 规则判定:
50 < min_trx_id (100)。说明这行数据在拍快照前早就提交了。 - 读取结果:事务 A 读到 余额 1000。
第二步:T2 与 T3 时刻,形成 Undo Log 版本链
事务 B 和 事务 C 先后修改了这行数据。InnoDB 不会抹掉老数据,而是通过 roll_pointer 把它们串成了铁链。
到了 T3 时刻,底层的真实数据结构变成了这样(这就是版本链):
[最新版本] 余额 3000
trx_id=300↓ (roll_pointer 指向下个节点)[历史版本] 余额 2000trx_id=200↓ (roll_pointer 指向下个节点)[最老版本] 余额 1000trx_id=50
第三步:T4 时刻,利用 Read View 顺藤摸瓜(核心机制!) 事务 A 第二次执行 SELECT。 因为是 RR 隔离级别,事务 A 沿用 T1 时刻生成的那张老快照!
现在,事务 A 顺着版本链,从最新数据开始,逐一核对它的 Read View 规则:
查验最新版本:余额 3000,
trx_id=300- 规则判定:
300 >= max_trx_id (101)。 - 结论:这个版本属于“未来的事务”,对我 ❌ 不可见。顺着指针往下找!
- 规则判定:
查验中间版本:余额 2000,
trx_id=200- 规则判定:
200 >= max_trx_id (101)。 - 结论:这个版本也是在我拍快照之后才冒出来的“未来事务”,虽然它已经提交了(T2时刻),但对我依然 ❌ 不可见。继续往下找!
- 规则判定:
查验最老版本:余额 1000,
trx_id=50- 规则判定:
50 < min_trx_id (100)。 - 结论:这个版本在我拍快照之前就已经存在且提交了。✅ 可见!
- 规则判定:
最终结果:事务 A 在 T4 时刻查到的依然是 余额 1000。
总结与升华
通过上面的推演,我们可以清晰地看到 MVCC 的三大法宝是如何合作的:
- 隐藏字段 + Undo Log:负责在后台默默记录所有的历史版本,不让任何一次修改丢失。
- Read View:就是一把“尺子”或者“过滤网”。它利用简单的比较大小运算(
trx_id与min_trx_id/max_trx_id比对),快速筛掉那些不该被当前事务看到的未来数据或未提交数据。 - RR 级别的魔力:只要快照(Read View)不更新,外界怎么修改,当前事务顺着版本链摸到的,永远是最初的那一份数据。这就是“可重复读”的终极奥义!
IF
IF 是 SQL 中的一个条件函数,用于根据指定的条件返回不同的结果。它的基本语法如下:
IF(condition, true_value, false_value)其中:
condition:一个表达式,返回布尔值(true 或 false)。true_value:当条件为 true 时返回的值。false_value:当条件为 false 时返回的值。
Case
CASE 是 SQL 中的一个条件表达式,用于根据多个条件返回不同的结果。它的基本语法如下:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
ELSE default_result
END其中:
condition1,condition2, ...:一个或多个条件表达式,返回布尔值(true 或 false)。result1,result2, ...:当对应条件为 true 时返回的值。default_result:当所有条件都为 false 时返回的默认值(可选)。
IFNULl / COALESCE
IFNULL 和 COALESCE 都是 SQL 中用于处理 NULL 值的函数,但它们的功能和用法略有不同。
- IFNULL:IFNULL 函数接受两个参数,如果第一个参数为 NULL,则返回第二个参数的值;否则返回第一个参数的值。语法如下:
IFNULL(expression, alt_value)- COALESCE:COALESCE 函数接受多个参数,返回第一个非 NULL 的值。如果所有参数都为 NULL,则返回 NULL。语法如下:
COALESCE(expression1, expression2, ..., expressionN)COALESCE 三大经典实战场景
给报表“补零” (最常用)
在计算总额或显示奖金时,NULL 会导致整个计算失效(任何数 + NULL = NULL)。
SELECT
name,
-- 如果奖金是 NULL,就显示 0,防止报表出现空白或计算错误
COALESCE(bonus, 0) AS actual_bonus
FROM Employees;多级备选联系方式
业务中常有“首选、备选”逻辑,COALESCE 像剥洋葱一样从左往右找。
SELECT
name,
-- 顺序:有手机取手机 -> 没手机取座机 -> 没座机取邮箱 -> 全没取“无”
COALESCE(mobile, home_phone, email, 'No Contact') AS contact_info
FROM Customers;处理 JOIN 后的缺失数据
当使用 LEFT JOIN 时,右表匹配不到的数据会显示为 NULL,用它来美化结果。
SELECT
c.name,
COALESCE(SUM(o.amount), 0) AS total_spent
FROM Customers c
LEFT JOIN Orders o ON c.id = o.customer_id
GROUP BY c.name;COALESCE vs IFNULL (MySQL)
| 特性 | COALESCE | IFNULL |
|---|---|---|
| 参数数量 | 无限多个 (灵活) | 只能有 2 个 (死板) |
| 通用性 | 标准 SQL (全数据库通用) | 仅限 MySQL |
| 处理逻辑 | 寻找第一个非空值 | 如果 A 为空则取 B |
数值操作(整数与浮点数)
基础算术运算
| 运算符/函数 | 说明 | 示例与结果 |
|---|---|---|
+, -, *, / | 加减乘除 | SELECT 10 / 3; ➡️ 3.3333 |
% 或 MOD(a, b) | 取余数(模运算),常用于判断奇偶数 | SELECT MOD(10, 3); ➡️ 1 |
ABS(x) | 取绝对值 | SELECT ABS(-5.5); ➡️ 5.5 |
进阶取整与精度控制 (高频考点)
处理金额或占比时,如何控制小数位是必考项。
| 函数 | 说明 | 示例与结果 |
|---|---|---|
ROUND(x, d) | 四舍五入,保留 d 位小数 | SELECT ROUND(3.1415, 2); ➡️ 3.14 |
CEIL(x) / CEILING | 向上取整(只要有小数就进位) | SELECT CEIL(3.01); ➡️ 4 |
FLOOR(x) | 向下取整(直接抹除小数部分) | SELECT FLOOR(3.99); ➡️ 3 |
TRUNCATE(x, d) | 暴力截断,不进行四舍五入 | SELECT TRUNCATE(3.999, 1); ➡️ 3.9 |
数学运算
| 函数 | 说明 | 示例与结果 |
|---|---|---|
POWER(x, y) / POW | 求 x 的 y 次方 | SELECT POWER(2, 3); ➡️ 8 |
SQRT(x) | 求平方根 | SELECT SQRT(16); ➡️ 4 |
SIGN(x) | 判断正负(正数返回1,负数返回-1,零返回0) | SELECT SIGN(-50); ➡️ -1 |
日期与时间操作
日期函数是数据分析的灵魂。我们上一题算“次日留存”用到的 DATE_ADD 就是其中的冰山一角。
获取当前时间
| 函数 | 说明 | 返回格式示例 |
|---|---|---|
NOW() / CURRENT_TIMESTAMP | 返回当前的日期 + 时间 | 2023-10-27 15:30:00 |
CURDATE() / CURRENT_DATE | 仅返回当前的日期 | 2023-10-27 |
CURTIME() / CURRENT_TIME | 仅返回当前的时间 | 15:30:00 |
日期的加减运算 (留存/流失分析必备)
| 函数 | 说明 | 示例与结果 |
|---|---|---|
DATE_ADD(date, INTERVAL expr unit) | 往后加时间(天/月/年) | DATE_ADD('2023-01-01', INTERVAL 1 DAY) ➡️ 2023-01-02 |
DATE_SUB(date, INTERVAL expr unit) | 往前减时间 | DATE_SUB('2023-01-01', INTERVAL 1 MONTH) ➡️ 2022-12-01 |
DATEDIFF(date1, date2) | 计算天数差(date1 - date2) | DATEDIFF('2023-01-05', '2023-01-01') ➡️ 4 |
TIMESTAMPDIFF(unit, dt1, dt2) | 计算精准时间差(可精确到秒/小时) | TIMESTAMPDIFF(HOUR, '10:00', '12:00') ➡️ 2 |
日期维度的提取与格式化
在做“按月统计”、“按年分组”时极其常用。
| 函数 | 说明 | 示例与结果 |
|---|---|---|
YEAR(date) | 提取年份 | SELECT YEAR('2023-10-27'); ➡️ 2023 |
MONTH(date) | 提取月份 | SELECT MONTH('2023-10-27'); ➡️ 10 |
DAY(date) | 提取天数 | SELECT DAY('2023-10-27'); ➡️ 27 |
DAYOFWEEK(date) | 提取星期几(1是周日,2是周一) | SELECT DAYOFWEEK('2023-10-27'); ➡️ 6 |
DATE_FORMAT(date, format) | 按指定格式输出字符串 | DATE_FORMAT('2023-10-27', '%Y年%m月') ➡️ 2023年10月 |
SQL 核心聚合函数速查指南 (配合 GROUP BY 使用)
绝对核心的“五大金刚”
这是日常取数和面试中最基础、必定会用到的 5 个函数:
| 聚合函数 | 核心作用 | 适用数据类型 | 经典实战场景 |
|---|---|---|---|
COUNT() | 计数(数一数圈子里有几条数据) | 任何类型 | 统计每个部门的员工人数;统计每个商品的总销量。 |
SUM() | 求和(把圈子里的值全加起来) | 仅限数值型 | 计算每个用户的历史总消费金额。 |
AVG() | 求平均值 | 仅限数值型 | 计算每个班级的平均成绩;计算客单价。 |
MAX() | 求最大值 | 数值、日期、字符串 | 找出每个部门的最高薪水;找出每个用户的最近一次登录时间。 |
MIN() | 求最小值 | 数值、日期、字符串 | 找出每个班级的最低分;找出每个用户的首次注册/下单时间。 |
(注:字符串类型的 MAX/MIN 会按照字典序比较,例如 Z 大于 A)
字符串拼接
除了算数字,有时我们需要把同一个圈子里的文本拼成一句话(比如把同一个部门的所有员工名字用逗号连起来展示)。这是极佳的面试加分项:
MySQL 环境:GROUP_CONCAT()
-- 按部门分组,把同部门的员工名字用逗号和空格拼起来
SELECT
department,
GROUP_CONCAT(name SEPARATOR ', ') AS all_employees
FROM employees
GROUP BY department;SQL 窗口函数 (Window Functions) 核心速查笔记
在 SQL 中,GROUP BY 会把多行数据“绞碎”压缩成一行,从而丢失个体明细。而**窗口函数(Window Functions)**就像是给数据戴上了“透视眼镜”:它能在后台把数据分好圈子并计算出结果,然后把这个结果像“贴纸”一样贴在每一行数据后面。总行数不变,既保留了微观明细,又获得了宏观统计值。
核心语法(万能公式)
所有的窗口函数都遵循以下标准结构:
函数名(字段) OVER ( PARTITION BY 分组字段 ORDER BY 排序字段 ASC/DESC ROWS BETWEEN 范围)OVER():触发窗口函数的“魔法结界”标志。只要看到它,就是窗口函数。PARTITION BY:怎么划定圈子?(相当于窗口里的GROUP BY,例如按department_id划分)。如果不写,则把整张表当成一个大圈子。ORDER BY:在圈子内部怎么排队?(例如按salary DESC从高到低排)。- ROWS BETWEEN [起点] AND [终点]:
- 最近 7 天:ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
- 前后各 1 天:ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
- 历史至今:ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
选择 ROWS 还是 RANGE?
ROWS (按行数):死脑筋,只数行数。不管日期连不连续,我就数前 6 行。ROWS BETWEEN 6 PRECEDING RANGE (按数值范围):聪明点,看数值间隔。如果 1 号后面直接跳到了 10 号,RANGE 发现中间断了,就不会乱加。RANGE BETWEEN INTERVAL 6 DAY PRECEDING
三大实战流派 (面试必考)
排名流派 (找 Top N / 首次、末次行为必备)
处理分组排名问题时,这三个函数是绝对的主力:
| 函数 | 排名逻辑 | 遇到同分情况的处理 | 示例 |
|---|---|---|---|
ROW_NUMBER() | 无情发号器 | 强制分出先后,绝对不并列 | 1, 2, 3, 4 |
RANK() | 跳跃排名 | 名次相同,但会占坑位 | 1, 1, 3, 4 |
DENSE_RANK() | 密集排名 | 名次相同,且不占坑位 | 1, 1, 2, 3 |
宏观聚合流派 (保留明细看全局)
直接把五大基础聚合函数(SUM, AVG, MAX, MIN, COUNT)放在 OVER() 前面。
- 经典场景:在输出每个员工薪水的同时,在旁边加上“本部门平均薪水”作对比。
- 滚动求和 (Running Total):只要在
OVER()里加上ORDER BY,SUM()就会自动变成“从第一行一直加到当前行”的累计求和机制(完美解决“巴士超载”等累计阈值问题)。
前后偏移流派 (计算间隔 / 连续性必备)
极其强大的“时光机”函数,可以站在当前行,去读取同一组里其他行的数据。
| 函数 | 核心作用 | 经典实战场景 |
|---|---|---|
LAG(字段, N) | 读取上一行(或往上第 N 行)的数据 | 计算“本次购买与上次购买的间隔天数” |
LEAD(字段, N) | 读取下一行(或往下第 N 行)的数据 | 计算“今天与明天的温度差” |
(注:如果找不到上一行或下一行,默认会返回 NULL)
黄金避坑法则
- 执行顺序极其靠后:窗口函数在数据库里的执行优先级非常低,仅排在
ORDER BY之前。它绝对不能直接写在WHERE或者HAVING里面作为过滤条件! - 正确过滤姿势:如果想用窗口函数的结果来过滤(例如:找出排名第 1 的人),必须在外面套一层子查询。在内层生成排名,然后在外层用
WHERE 排名 = 1来过滤。
经典例子
案例一:分组内 Top N 问题(最常见)
业务场景:老板说:“给我拉一份每个部门薪水排名前 3 的员工名单。” 痛点:普通 GROUP BY 只能查出部门最高薪水,无法同时保留员工名字,更无法取前 3 名。
核心写法(DENSE_RANK 搭配子查询):
SELECT department_id, employee_name, salary
FROM (
-- 核心:在内部给每个部门的员工按薪水打上排名标签
SELECT
department_id,
employee_name,
salary,
DENSE_RANK() OVER(PARTITION BY department_id ORDER BY salary DESC) as rnk
FROM Employees
) AS ranked_table
-- 在外层直接过滤排名标签
WHERE rnk <= 3;(注:这里用 DENSE_RANK() 是因为如果两个人并列第一,下一个依然是第二名,不会漏掉名额。)
案例二:计算同环比 / 间隔时间(LAG/LEAD 时光机)
业务场景:计算每个用户“本次下单”与“上一次下单”之间隔了多少天。 痛点:普通 SQL 很难让同一张表里相邻的两行数据进行相减。
核心写法(LAG 获取上一行):
SELECT
user_id,
order_date,
-- 用 LAG 把同用户上一行的下单日期拉到当前行来
LAG(order_date, 1) OVER(PARTITION BY user_id ORDER BY order_date ASC) AS prev_date,
-- 直接用当前日期减去上一行日期,得到间隔天数
DATEDIFF(
order_date,
LAG(order_date, 1) OVER(PARTITION BY user_id ORDER BY order_date ASC)
) AS diff_days
FROM Orders;(注:算出来的第一行 prev_date 会是 NULL,因为没有上一次记录了。)
案例三:终极 Boss —— 找出连续登录 3 天以上的玩家
业务场景:游戏公司做活动,需要给连续登录 3 天及以上的玩家发奖励。 痛点:连续性的日期极难判断,因为你不知道玩家到底是从哪一天开始连续的。
核心黑科技:“日期减去排序差值法” 这个套路极其精妙:如果日期是连续的(1号、2号、3号),而排名也是连续的(第1名、第2名、第3名)。那么日期减去它的排名,一定会得到一个相同的“基准日期”!
2023-10-01减 1天 =2023-09-302023-10-02减 2天 =2023-09-302023-10-03减 3天 =2023-09-30
满分代码(三步走):
SELECT DISTINCT player_id
FROM (
-- 第三步:按照玩家和算出来的“基准日期”进行分组
SELECT player_id, base_date
FROM (
-- 第二步:用日期减去它的名次,算出“基准日期”
SELECT
player_id,
login_date,
DATE_SUB(login_date, INTERVAL rn DAY) AS base_date
FROM (
-- 第一步:一天登录多次只算一次,先去重,然后按时间打上连号排名
SELECT DISTINCT player_id, login_date,
ROW_NUMBER() OVER(PARTITION BY player_id ORDER BY login_date ASC) AS rn
FROM Activity
) step1
) step2
GROUP BY player_id, base_date
-- 第四步:只要同一个基准日期下面攒够了 3 条记录,说明就是连续 3 天!
HAVING COUNT(*) >= 3
) final_result;一些面试题
LEFT JOIN 中条件写在 ON 和 WHERE 里的致命区别
- 写在
ON里:这是连接过程中的匹配条件。即使右表找不到匹配的数据,左表的数据也一定会保留(右表字段补NULL)。 - 写在
WHERE里:这是连接完成后的全局过滤条件。如果不符合条件,整行数据(连同本该保留的左表数据)会被直接砍掉,导致LEFT JOIN退化成INNER JOIN。
INNER JOIN 和 逗号多表查询(隐式连接)的区别
- 结论:性能完全一样,但强烈推荐
INNER JOIN。 - 原因:
INNER JOIN ... ON是 SQL-92 标准,将“表连接逻辑”与“业务过滤逻辑(WHERE)”严格拆分,可读性极高,且能避免漏写条件导致的“全表笛卡尔积”灾难。
COUNT(*)、COUNT(1) 和 COUNT(字段名) 的区别
| 函数写法 | 统计维度 | 对 NULL 的处理 | 性能/底层逻辑 |
|---|---|---|---|
COUNT(*) | 总行数 | 包含 NULL 的行 | 极高,优化器直接走最小可用索引。(SQL 标准推荐) |
COUNT(1) | 总行数 | 包含 NULL 的行 | 极高,底层执行逻辑与 COUNT(*) 完全等价。 |
COUNT(字段) | 特定列非空值 | 完全无视 NULL | 较差,需逐行提取字段并做 IS NOT NULL 判断。 |
- 避坑口诀:只要是算“总数/总行数”,永远无脑用
COUNT(*)。
IN 和 EXISTS 的区别与选型(小表驱动大表原则)
这两个函数都用于判断“A 表数据是否在 B 表中”,但底层驱动逻辑完全相反:
EXISTS(半连接 / 探测器):- 逻辑:外表逐行扫描,丢探测器去内表找。找到第一个匹配项立刻返回
TRUE(短路机制),不全表扫描。 - 适用场景:外表小,内表大(或者内表字段有高效索引)。
- 逻辑:外表逐行扫描,丢探测器去内表找。找到第一个匹配项立刻返回
IN(哈希比对):- 逻辑:先把内表数据全部查出来放在内存里,然后让外表去比对。
- 适用场景:外表大,内表小。
如何获取每个分组里的第一条/Top N 数据?
- ❌ 错误解法:直接
GROUP BY取明细字段(会报错或返回错乱数据)。 - ✅ 标准解法(大厂最爱):使用窗口函数
ROW_NUMBER()。
-- 核心公式:按某字段分组,按某字段排序,打上行号,最后在外层 WHERE 过滤行号
ROW_NUMBER() OVER(PARTITION BY 分组字段 ORDER BY 排序字段 DESC) as rn