
LLM
本地部署DeepSeek并微调
创建环境
python
# 安装unsloth包。是一个用于微调大型语言模型的工具,可以加速并减少内存。
!pip install unsloth
!pip uninstall unsloth -y && pip install --upgrade --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
# 前者适用于量化和优化模型的库,减少模型所占内存
# 后者包含了一些预训练模型或其他工具
!pip install bitsandbytes unsloth_zoounsloth是一个开源的大语言模型微调工具。可以高效微调(通过手写GPU内核和优化计算步骤、内存优化等方式),且动态量化、支持长上下文。对特定的模型进行了专门的设定,来优化这些模型本地部署的表现。  建议去读一下官方文档:unsloth
建议去读一下官方文档:unsloth
加载预训练模型
python
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # 处理文本的最大长度
dtype = None # 模型自动选择合适的精度
load_in_4bit = True # 使用4位量化来节省内存
# 加载预训练模型,并获取tokenizer工具
model,tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
)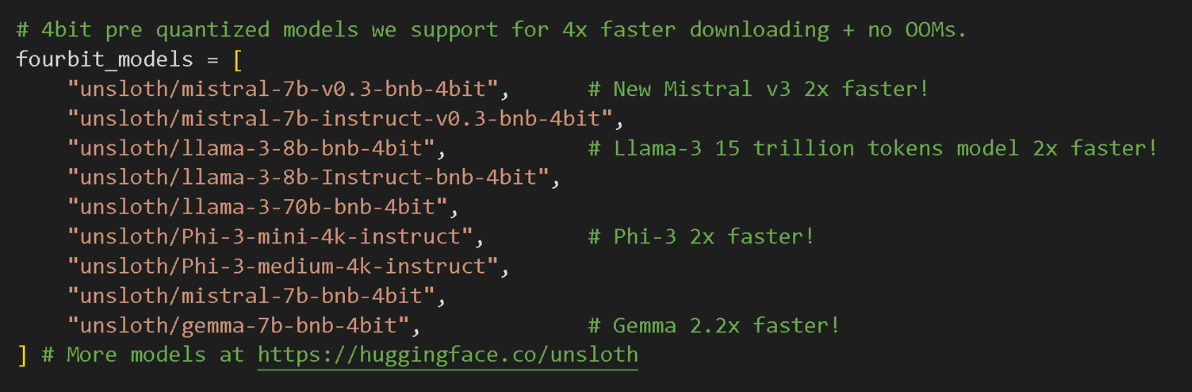 支持的模型选择,上面是新支持的deepseek。
支持的模型选择,上面是新支持的deepseek。
max_seq_length决定了模型的上下文长度。设为2048进行尝试,但是实际无限制。dtype决定模型选择的精度。较新的GPU可以选择torch.float16或者torch.bfloat16load_in_4bit决定使用4位量化来节省内存。4位量化本质是将权重转换为一组有限数字,单精度会下降1%到2%。
这里可以设置一个保存点:
python
checkpoint_dir = "/outputs_DeepSeek-R1-Distill-Llama-8B"
# 通过验证 trainer_state.json 文件是否存在来检查特定模型的检查点是否存在。
def is_model_processed(model_name):
checkpoint_path = os.path.join(checkpoint_dir, model_name.split("/")[-1], "checkpoint-500", "trainer_state.json")
print(f"Checking checkpoint path: {checkpoint_path}")
return os.path.exists(checkpoint_path)
# 通过创建 .done 文件将模型标记为已处理,表明模型已成功训练并保存。
def mark_model_as_processed(model_name):
checkpoint_file = os.path.join(checkpoint_dir, f"{model_name.replace('/', '_')}.done")
print(f"Marking model as processed: {checkpoint_file}")
with open(checkpoint_file, 'w') as f:
f.write("")微调前测试
python
prompt_style = """以下是描述任务的指令,以及提供进一步上下文的输入。
请写出一个适当完成请求的回答。
在回答之前,请仔细思考问题,并创建一个逻辑连贯的思考过程,以确保回答准确无误。
### 指令:
你是一位精通卜卦、星象和运势预测的算命大师。
请回答以下算命问题。
### 问题:
{}
### 回答:
<think>{}"""
# 定义提示风格的字符串模版,用于格式化问题
question = "1992年闰四月初九巳时生人,女,想了解健康运势"
# 定义具体的算命问题先调用模型查看效果:
python
FastLanguageModel.for_inference(model)
# 准备模型以进行推理
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
# 使用tokenizer对格式化的问题进行编码,并移动到GPU
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
# 使用模型生成回答
response = tokenizer.batch_decode(outputs)
# 解码模型生成的输出为可读文本
print(response[0])
# 打印回答定义训练出来的模型风格
python
train_prompt_style = """以下是描述任务的指令,以及提供进一步上下文的输入。
请写出一个适当完成请求的回答。
在回答之前,请仔细思考问题,并创建一个逻辑连贯的思考过程,以确保回答准确无误。
### 指令:
你是一位精通八字算命、紫微斗数、风水、易经卦象、塔罗牌占卜、星象、面相手相和运势预测等方面的算命大师。
请回答以下算命问题。
### 问题:
{}
### 回答:
<思考>
{}
</思考>
{}"""上面这个有点绝对了,我们可以这么定义:
python
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""加载数据集
python
# 定义结束标记(EOS_TOKEN),用于指示文本的结束
EOS_TOKEN = tokenizer.eos_token # 必须添加结束标记
# 导入数据集加载函数
from datasets import load_dataset
# 加载指定数据集,选择中文和训练集前500条数据
dataset = load_dataset("Conard/fortune-telling", 'default', split = "train[0:200]", trust_remote_code=True)
# 打印数据集的列名,查看有哪些字段
print(dataset.column_names)以上是使用huggingface上已有的数据集,可以直接去huggingface上搜索查看。 数据集有很多种形式,去了解下sharegpt。 正常情况下需要自行处理、验证,找到合适的方式如下:
python
def preprocess_dataset(input_path, output_path, train_path, val_path, augmentation_factor=3):
print("Preprocessing, validating, and augmenting dataset...")
valid_entries = 0
def clean_text(text):
"""Normalize and clean text."""
text = re.sub(r"[^a-zA-Z0-9ğüşıöçĞÜŞİÖÇ.,!?\\-]", " ", text) # Remove unwanted characters
text = re.sub(r"\s+", " ", text).strip() # Remove extra spaces
return text.lower() # Normalize to lowercase
def augment_text(text):
"""Create variations of text for augmentation."""
"""就是通过更换同义词,使得数据更多更全面"""
synonyms = {
"highlight": ["emphasize", "focus on", "spotlight"],
"identify": ["detect", "recognize", "pinpoint"],
"discuss": ["elaborate on", "examine", "analyze"],
"important": ["crucial", "key", "essential"]
}
for word, replacements in synonyms.items():
if word in text:
text = text.replace(word, random.choice(replacements))
return text
augmented_data = []
with open(input_path, 'r', encoding='utf-8') as infile:
for line in infile:
try:
data = json.loads(line)
if 'instruction' in data and 'input' in data and 'output' in data:
cleaned_data = {
"instruction": clean_text(data.get("instruction", "")),
"input": clean_text(data.get("input", "")),
"output": clean_text(data.get("output", ""))
}
augmented_data.append(cleaned_data)
valid_entries += 1
for _ in range(augmentation_factor):
augmented_entry = {
"instruction": augment_text(cleaned_data['instruction']),
"input": augment_text(cleaned_data['input']),
"output": augment_text(cleaned_data['output'])
}
augmented_data.append(augmented_entry)
except json.JSONDecodeError:
print("Skipping invalid JSON line.")
print(f"Dataset preprocessing complete. Valid entries: {valid_entries}")
# Split into train and validation
# train_test_split:来自 scikit-learn 的函数,用于将数据集拆分为训练集和验证集。
train_data, val_data = train_test_split(augmented_data, test_size=0.2, random_state=42)
# Save datasets
with open(output_path, 'w', encoding='utf-8') as outfile:
for entry in augmented_data:
outfile.write(json.dumps(entry, ensure_ascii=False) + '\n')
with open(train_path, 'w', encoding='utf-8') as trainfile:
for entry in train_data:
trainfile.write(json.dumps(entry, ensure_ascii=False) + '\n')
with open(val_path, 'w', encoding='utf-8') as valfile:
for entry in val_data:
valfile.write(json.dumps(entry, ensure_ascii=False) + '\n')
print(f"Enhanced dataset saved to {output_path}. Train and validation sets saved to {train_path} and {val_path}.")共有三个方法:
- clean_text:通过删除不需要的字符、多余的空格并将文本转换为小写来清理和规范化文本。后期需要调整正则表达式以适应不同的语言或特定的数据集要求。
- augment_text:通过用同义词替换特定单词来创建变体,从而增强数据集。后期可以结合更复杂的增强技术,例如释义或反向翻译,以增加数据多样性。
- preprocess_dataset: 读取输入数据集,清理和增强数据,将其拆分为训练和验证集,并保存处理后的数据。后期可以增强错误日志记录以捕获有关有问题的数据条目的更多详细信息。
格式化数据集
python
def formatting_prompts_func(examples):
# 从数据集中提取问题、复杂思考过程和回答
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = [] #用于存储格式化后的文本
# 遍历每个问题、思考过程和回答,进行格式化
for input, cot, output in zip(inputs, cots, outputs):
# 使用字符串模版插入数据,并加上结束标记
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text) # 加入到列表中
return {
"text": texts, #返回所有格式化文本的字典
}
dataset = dataset.map(formatting_prompts_func, batched = True)
dataset["text"][0]同理,还是有点绝对了。可以用以下方式处理数据集:
python
EOS_TOKEN = tokenizer.eos_token # Ensures proper sequence termination
def formatting_prompts_func(examples):
print("Formatting dataset prompts...")
instructions = examples.get("instruction", "")
inputs = examples.get("input", "")
outputs = examples.get("output", "")
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return {"text": texts}除此之外,还可以用以下方式加载和格式化训练/验证数据集:
python
print(f"Loading train dataset from: {train_dataset_path}")
train_dataset = load_dataset("json", data_files=train_dataset_path, split="train")
print(f"Loading validation dataset from: {val_dataset_path}")
val_dataset = load_dataset("json", data_files=val_dataset_path, split="train")
train_dataset = train_dataset.map(formatting_prompts_func, batched=True)
val_dataset = val_dataset.map(formatting_prompts_func, batched=True)
print("Datasets loaded and formatted.")模型微调准备
python
FastLanguageModel.for_training(model)
# 使用LoRA技术
model = FastLanguageModel.get_peft_model(
model, # 传入加载好的预训练模型
r=16, # 设置LoRA的秩,决定添加的可训练参数数量
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", " down_proj"], # 制定模型中需要微调的关键模块
lora_alpha=16, # 设置LoRA的超参数,影响可训练参数的训练方式
lora_dropout=0, # 设置防止过拟合的参数,这里设置为0表示不丢弃任何参数
bias="none", # 设置是否添加偏置项,这里设置为"none"表示不添加
use_gradient_checkpointing="unsloth", # 使用优化技术节省显存并支持更大的批量大小
random_state=3407, # 设置随机种子,确保每次运行代码时模型的初始化方式相同
use_rslora=False, # 设置是否使用Rank Stabilized LoRA 技术,这里设置为 False 表示不使用
loftq_config=None, # 设置是否使用LoftQ技术,这里设置为 None 表示不使用
)上面参数的含义:
r:微调过程的等级,决定添加的可训练参数数量。过高会占用更多内存、速度过慢且可能过拟合。推荐8,16,32,64,128。["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", " down_proj"]:即所有的模块,可以删除部分以减少内存使用量,但是不推荐。lora_alpha:微调的比例因子。较大的数字可以使模型了解更多信息,但也有可能促进过拟合。推荐为r或r的倍数。lora_dropout:设置防止过拟合的参数,影响不大。这里设置为0表示不丢弃任何参数,也是推荐为0。bias:设置是否添加偏置项,设置为"none"表示不添加。use_gradient_checkpointing:使用优化技术节省显存并支持更大的批量大小。具体的优化实现方法。random_state:通过设置随机种子确保可重复性。
配置微调参数
python
from trl import SFTTrainer # 导入 SFTTrainer,用于监督式微调
from transformers import TrainingArguments # 导入 TrainingArguments,用于设置训练参数
from unsloth import is_bfloat16_supported # 导入函数,检查是否支持 bfloat16 数据格式
# 用于检查点恢复:
# resume_checkpoint_dir = os.path.join(model_dir, "checkpoint-500")
# print(f"Before Resuming from checkpoint: {resume_checkpoint_dir}")
# if os.path.exists(os.path.join(resume_checkpoint_dir, "trainer_state.json")):
# print(f"Resuming from checkpoint: {resume_checkpoint_dir}")
# print(f"Checkpoint Files: {os.listdir(resume_checkpoint_dir)}")
# resume_from_checkpoint = resume_checkpoint_dir
# else:
# print("No valid checkpoint found, starting from scratch.")
# resume_from_checkpoint = None
# 创建一个 SFTTrainer 实例
trainer = SFTTrainer(
model=model, # 传入要微调的模型
tokenizer=tokenizer, # 传入 tokenizer,用于处理文本数据
train_dataset=dataset, # 传入训练数据集
dataset_text_field="text", # 指定数据集中文本字段的名称
max_seq_length=max_seq_length, # 设置最大序列长度
dataset_num_proc=2, # 设置数据处理的并行进程数
packing=False, # 是否启用打包功能(这里设置为False,打包可以让训练更快,但可能影响效果)
# 定义训练参数
args=TrainingArguments(
per_device_train_batch_size=2, # 每个设备(如GPU)上的批量大小
gradient_accumulation_steps=4, # 梯度累计步数,用于模拟大批次训练
# Batch Size为上面两个数字相乘
warmup_steps=5, # 预热步数,训练开始时学习率逐渐增加的步数
max_steps=75, # 最大训练步数
learning_rate=2e-4, # 学习率,模型学习新知识的速度
fp16=not is_bfloat16_supported(), # 是否使用 fp16 格式加速训练(如果环境不支持 bfloat16)
bf16=is_bfloat16_supported(), # 是否使用 bfloat16 格式加速训练(如果环境支持)
logging_steps=1, # 每隔多少步记录一次训练日志
optim="adamw_8bit", # 使用的优化器,用于调整模型参数,用于提高内存效率。
weight_decay=0.01, # 权重衰减,防止模型过拟合
lr_scheduler_type="linear", # 学习率调度器类型,控制学习率的变化方式
seed=3407, # 随机种子,确保训练结果可复现
output_dir="outputs", # 训练结果保存的目录
report_to="none", # 是否将训练结果报告到外部工具(如 WandB),这里设置为不报告
# resume_from_checkpoint=resume_from_checkpoint, # 传递检查点位置
)
)
# 训练轮数(Epochs)为最大训练步数*每一步训练大小/数量集大小- SFTTrainer:来自trl库的训练器类,专门为了监督微调而设计。
开始训练
python
trainer_stats = trainer.train()如下,可以从检查点开始继续训练,但是要在上面定义SFTTrainer的时候加上定义!!!:
python
trainer_stats = trainer.train(resume_from_checkpoint=resume_from_checkpoint)保存模型为GGUF格式
python
from google.colab import userdata
# 从 Google Colab 用户数据中获取Hugging Face的API令牌
HUGGINGFACE_TOKEN = userdata.get('HUGGINGFACE_TOKEN')
# 将模型保存为8位量化格式
# 这种格式文件小且运行快,适合部署到资源受限的设备
if True: model.save_pretrained_gguf("model", tokenizer,)
# 十六位
if False: model.save_pretrained_gguf("model_f16", tokenizer, quantization_method="f16")
# 四位,精度低
if False: model.save_pretrained_gguf("model", tokenizer, quantization_method="q4_k_m")推送到HuggingFace
python
# 导入 Hugging Face Hub 的 create_repo 函数,用于创建一个新的模型仓库
from huggingface_hub import create_repo
# 在 Hugging Face Hub 上创建一个新的模型仓库
create_repo("Conard/fortunetelling", token=HUGGINGFACE_TOKEN, exist_ok=True)
# 将模型和分词器上传到 Hugging Face Hub 上的仓库
model.push_to_hub_gguf("Conard/fortunetelling", tokenizer, token=HUGGINGFACE_TOKEN)sharegpt
Instruction Input Output
输入可能为<无输入>。Instruction指导gpt应该做的事,input与instrcution相关,例如当instruction为重写这段话,使其简洁清晰。时,input就可以为那句话。
Kaggle
微调具体代码
python
# 检查环境
import torch
from transformers.utils import is_torch_sdpa_available
print(f"ROCm 版本: {torch.version.hip}")
print(f"SDPA 可用: {is_torch_sdpa_available()}")
print(torch.__version__) # 应该显示 rocmX.X
print(torch.cuda.is_available()) # 如果是 AMD GPU,可能是 False
print(torch.device('cuda').type)
print(torch.cuda.is_bf16_supported()) # 返回 True 则支持
from transformers import AutoTokenizer
model_name = "/root/deepseekr1-1.5b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# tokenizer.padding_side='right'
print('模型填充方向:')
print(tokenizer.padding_side)
print('模型特殊填充:')
print(tokenizer.special_tokens_map)
print(tokenizer.bos_token_id)
print(tokenizer.pad_token_id)
print("---初次模型加载成功---")
from datasets import load_dataset, DatasetDict, Dataset
import torch
dataset = load_dataset('/hpc-instruct')
max_context_length = 512
print("原始数据集:")
print(dataset)
print(dataset['train'][0])
def format_for_finetuning(examples):
inputs = []
outputs = []
for i in range(len(examples["problem statement"])):
# 构造输入(可自定义,例如拼接语言和问题)
input_text = f"Language: {examples['language'][i]}\nProblem: {examples['problem statement'][i]}\nSolution:"
output_text = f"{examples['solution'][i]}{tokenizer.eos_token}"
inputs.append(input_text)
outputs.append(output_text)
return {"input": inputs, "output": outputs}
# 应用预处理
formatted_dataset = dataset.map(format_for_finetuning, batched=True, remove_columns=dataset["train"].column_names)
print('\n')
print("处理完的数据:")
print(formatted_dataset['train'][0])
def tokenize_function(examples):
model_inputs = tokenizer(
examples["input"], # 输入文本(如 "Language: en\nProblem: ...\nSolution:")
truncation=True, # 如果超过 max_length,自动截断
max_length=int(max_context_length/2), # 输入部分的最大 token 长度(给 output 留出空间,总长 max_context_length)
padding=False, # 不填充(后续手动处理)
)
model_outputs = tokenizer(
text_target=examples["output"], # 关键修改:指定 text_target
truncation=True,
max_length=int(max_context_length/2),
padding=False,
)
# 拼接并创建labels(输入部分设为-100,输出部分保留eos_token)
input_ids = [i + o for i, o in zip(model_inputs["input_ids"], model_outputs["input_ids"])]
labels = [[-100] * len(i) + o for i, o in zip(model_inputs["input_ids"], model_outputs["input_ids"])]
# 截断到max_length
input_ids = [seq[:max_context_length] for seq in input_ids]
labels = [seq[:max_context_length] for seq in labels]
# 统一填充(labels空白部分用-100)
padded_input_ids = []
padded_attention_mask = []
padded_labels = []
for inp, lab in zip(input_ids, labels):
pad_len = max_context_length - len(inp)
if tokenizer.padding_side == "right":
padded_input_ids.append(inp + [tokenizer.pad_token_id] * pad_len)
padded_attention_mask.append([1] * len(inp) + [0] * pad_len)
padded_labels.append(lab + [-100] * pad_len)
else:
padded_input_ids.append([tokenizer.pad_token_id] * pad_len + inp)
padded_attention_mask.append([0] * pad_len + [1] * len(inp))
padded_labels.append([-100] * pad_len + lab)
return {
"input_ids": torch.tensor(padded_input_ids),
"attention_mask": torch.tensor(padded_attention_mask),
"labels": torch.tensor(padded_labels),
}
train_dataset = formatted_dataset["train"].select(range(10000)) # 选择训练集(或其他分割)
print('\n')
print('训练的数据条数为:')
print(len(train_dataset))
# 应用Tokenization
tokenized_dataset = train_dataset.map(tokenize_function, batched=True)
print('\n')
print("经过tokenizer的数据:")
print(tokenized_dataset[0])
# 测试集和训练集是1:9的关系
split_dataset = tokenized_dataset.train_test_split(test_size=0.1)
train_dataset = split_dataset["train"]
eval_dataset = split_dataset["test"]
print(f"train dataset的长度为:{len(train_dataset)}")
print(f"eval dataset的长度为:{len(eval_dataset)}")
from transformers import BitsAndBytesConfig, AutoModelForCausalLM
import os
# os.environ["CUDA_VISIBLE_DEVICES"] = "0,1" # 指定使用两块 GPU
# nf4_config = BitsAndBytesConfig(load_in_4bit=True)
# torch_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16
os.environ["TOKENIZERS_PARALLELISM"] = "true"
model = AutoModelForCausalLM.from_pretrained(
model_name,
attn_implementation="sdpa", # 非 Flash 的 SDPA 实现
device_map="auto"
# 量化不支持
# quantization_config=nf4_config,
# 稍微好一点的,默认的
# 最基础
# attn_implementation="eager",
# 不支持
# attn_implementation="flash_attention_2",
# torch_dtype=torch_dtype,
)
print(f"模型分配的设备: {model.hf_device_map}") # 检查设备分配
print(f"当前注意力后端: {model.config._attn_implementation}")
from peft import get_peft_model, LoraConfig, TaskType
lora_config = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.1,
# bias="none",
bias="lora_only",
task_type=TaskType.CAUSAL_LM,
# target_modules=["q_proj", "v_proj"],
target_modules=["q_proj", "k_proj", "v_proj"] # 更高精度需求时
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
print("---Lora微调设置完毕---")
from transformers import TrainingArguments, Trainer
# 训练前初始化
import wandb
import datetime
from zoneinfo import ZoneInfo
os.environ['WANDB_NOTEBOOK_NAME'] = 'exp.ipynb' # 替换成你的笔记本文件名
training_args = TrainingArguments(
report_to="wandb", # 或"tensorboard"
run_name="deepseek-r1-distill-finetune",
output_dir="./finetune_models",
logging_dir="./logs",
num_train_epochs=3,
per_device_train_batch_size=8, # 根据GPU内存调整
gradient_accumulation_steps=8,
# 实际batch大小:8*8*2=64
dataloader_num_workers=4, # 每个 GPU 使用 4 个子进程加载数据
dataloader_prefetch_factor=2, # 预取数据量
learning_rate=2e-5,
fp16=True,
# gradient_checkpointing=True, # 显存不足时启用(用时间换空间,显存降20%-30%)
# warmup_steps=500, # 学习率预热
weight_decay=0.01,
# max_grad_norm=1.0, # 梯度裁剪
eval_strategy="steps", # 启用按步数评估
eval_steps=200, # 每200步评估一次
save_strategy="steps", # 启用按步数保存
save_steps=200, # 每200步保存一次
logging_steps=10,
save_total_limit=2,
# save_total_limit=2,
# eval_strategy="epoch", # 每个epoch评估一次
# save_strategy="epoch", # 每个epoch保存一次
# logging_steps=1,
# 以下是额外添加的,配合callbacks=[EarlyStoppingCallback(early_stopping_patience=3)]
load_best_model_at_end=True,
metric_for_best_model="eval_loss",
greater_is_better=False, # eval_loss越小越好(如用准确率则需True)
label_names=["labels"], # 关键:避免 PEFT 的警告
)
wandb.init(
project="deepseek-finetune",
name=f"deepseek-finetune-{datetime.datetime.now(tz=ZoneInfo('Asia/Shanghai')).strftime('%Y%m%d-%H%M%S')}",
config={
"model_name": model_name,
"dataset": "data_prepare",
"learning_rate": 2e-5,
"batch_size": training_args.per_device_train_batch_size
* training_args.gradient_accumulation_steps
* torch.cuda.device_count(),
"epochs": 10
}
)
print("---训练参数设置完毕---")
from transformers import EarlyStoppingCallback
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)], # 早停
# compute_metrics=compute_metrics, # 添加自定义评估指标
# optimizers=(optimizer, lr_scheduler),
)
print("训练器加载完成")
print("---开始训练---")
trainer.train()
print("---训练完成---")
save_path = "./saved_model"
model.save_pretrained(save_path)
tokenizer.save_pretrained(save_path)
print("---lora模型已经保存---")
final_save_path = "./final_saved_path"
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained(model_name)
# 保存两个模型
model = PeftModel.from_pretrained(base_model, save_path)
model = model.merge_and_unload()
model.save_pretrained(final_save_path)
tokenizer.save_pretrained(final_save_path)
print("--- 全量模型saved---")困惑度
具体的定义上网搜吧,可以用来评估LM。但是实际上与交叉熵有直接关联,因此不必用这个属性来训练,用默认的交叉熵来训练就可以了。