
GO - basic knowledge
写在前面
别问我为什么go算作后端,因为我学他就是用来写自己的后端的。JAVA起项目太离谱了。 做笔记是因为每次学每次都会忘,将重点记下来好了。
switch
Go 的 switch 逻辑比传统的 C/Java 更简洁,最显著的特点是默认自动 break。
- 自动终止:匹配到一个
case并执行完毕后,程序会自动跳出switch,不需要显式写break。 - 多值匹配:一个
case可以同时测试多个可能的值,使用逗号,分隔。
switch score {
case "A", "B":
fmt.Println("表现优秀")
case "C":
fmt.Println("及格")
default:
fmt.Println("不及格")
}无表达式模式 (逻辑分支)
当 switch 后面不跟任何变量时,它就相当于一个更整洁的 if-else if-else 链。
- 适用场景:处理复杂的范围判断或多条件逻辑。
age := 20
switch {
case age < 18:
fmt.Println("未成年")
case age >= 18 && age < 60:
fmt.Println("劳动力")
default:
fmt.Println("退休")
}初始化语句
可以在 switch 关键字后直接声明一个变量,该变量的作用域仅限于整个 switch 块内部。
switch day := getWeekday(); day {
case "Saturday", "Sunday":
fmt.Println("周末休息")
default:
fmt.Println("工作日")
}
// 此处无法访问变量 day特殊关键字:fallthrough
如果你希望在执行完当前 case 后,继续执行下一个 case 的逻辑,必须使用 fallthrough。
- 强制穿透:它不会判断下一个
case的条件是否成立,而是直接进入。 - 位置要求:必须是
case块内部的最后一条语句。
num := 10
switch num {
case 10:
fmt.Println("匹配到 10")
fallthrough
case 20:
fmt.Println("由于 fallthrough,我也被执行了")
}类型分支 (Type Switch)
这是 Go 处理接口(interface{})时的杀手锏,用于识别变量的底层动态类型。
func identify(i interface{}) {
switch v := i.(type) {
case int:
fmt.Printf("整数: %d\n", v)
case string:
fmt.Printf("字符串: %s\n", v)
case bool:
fmt.Printf("布尔值: %v\n", v)
default:
fmt.Printf("未知类型: %T\n", v)
}
}注意事项与最佳实践
- 重复常量:
case后面的值不能重复(针对相同类型)。 - 默认分支:建议始终写一个
default分支来处理预期之外的情况,增强代码健壮性。 - 避免过度使用 fallthrough:逻辑穿透容易导致隐蔽的 Bug,除非有明确的业务逻辑需要,否则不建议使用。
数组
初始化
初始化不赋值即为空值。
复制
无论数组赋值给新的变量还是传递给函数都会产生新的数组副本!
传参
因为数组作为函数参数时,一方面会产生新的副本,另一方面如果定义了形参的长度,其长度会影响传参,所以会导致十分低效,函数一般用slice作为参数。
切片 slice
定义
指向数组的窗口,切分数组不会导致原数组被修改。planets[0:4]包括0不包括4,共四个元素。可以忽略其中任一或全部忽略(即[:]),分别代表数组开头或者结尾。
切分完以后修改原变量的值不会导致切片的值。切分字符串的时候计算的是字节数,而非字符数。
func main() {
// 先创建一个数组
testArray := [...]string{"a","b","c"}
// 创造切片的第一种方式
testSlice := testArray[:]
// 创造切片的第二种方式
test := []string{"a","b","c"}
}slice的长度不是函数参数的一部分。
append函数
可以向切片中添加元素,返回的也是slice
长度(length)&容量(capacity)
slice中的元素个数决定了slice的长度
如果slice的底层数组比slice还大,那么slice还有容量可供增长
可以使用len函数获取长度,使用cap函数获取容量
我的理解: 容量是切片数组原数组的长度,因为原数组长度不变,因此在切片上做append操作时最多到这个数组的结尾即结束。当slice的长度超出容量时,会将原数组进行复制,到新的数组并且增加容量(通常是原来数组的两倍),然后将切片指向新的数组。这会出现以下情况:
// 这时候改了testa会导致testb一起改变,test也会改变,因为三者为同一数组
test := [...]string{"a", "b", "c", "d"}
testa := test[1:]
testb := test[1:]
testa[1] = "f"
fmt.Println(testa)
fmt.Println(testb)
// 这时候改了testa不会改变testb和原数组,因为testa已经为新的数组的切片了
test := [...]string{"a", "b", "c", "d"}
testa := test[1:]
testa = append(testa, "e", "a", "b", "c", "d")
testb := test[1:]
testa[1] = "f"
fmt.Println(testa)
fmt.Println(testb)三索引切分操作
test[0:4:4]代表容量上线为4
// 下面的数组和切片指向的是三个完全不同的数据段
test := [...]string{"a", "b", "c", "d"}
testa := test[0:4:4]
testb := append(testa, "e")make预分配slice
通过make函数预分配,make([]string, 0, 10)代表长度为0,容量为10。可以互略第三个参数,此时代表长度和容量都为第二个参数。
test := make([]string, 0, 10)...
可变参数函数:...放在函数最后一个参数上(从0到若干个)
map
声明
声明为map[string]int,即需要指定键、值的类型。取的时候直接用中括号即可,可以直接修改。
mapping := make(map[string]int)
if value, ok := mapping["mapkey"]; ok {
fmt.Println("Value found:", value)
} else {
fmt.Println("Key 'mapkey' does not exist.")
}复制
map是不会直接被复制的。里面内容初始值为0。
计数器
可以使用map作为计数器,因为内容初始值为0。
删除
delete(m, key)set
可以模拟一个set。建议配合下面的迭代器一并阅读。
type Set[E comparable] struct {
m map[E]struct{}
}
func NewSet[E comparable]() Set[E] {
return Set[E]{m: make(map[E]struct{})}
}
func (s Set[E]) Add(e E) {
s.m[e] = struct{}{}
}
func (s Set[E]) Remove(e E) {
delete(s.m, e)
}
func (s Set[E]) Contains(e E) bool {
_, ok := s.m[e]
return ok
}struct
声明
// 这个仅指向point变量的结构体类型
var point struct {
x float64
y float64
}
// 这个使得location指向该结构体类型
type location struct {
x float64
y float64
}
// 初始化方式1
point := location{x: 1, y: 1}
// 初始化方式2
point2 := location{1, 2}复制
赋值给新的变量会产生新的副本!
编码为json
可以使用marshal函数,json.Marshal(),打印的时候用string强制类型转换。只会对被导出属性(大写)进行转换。
字符串标签
json:...类似于这种,gorm中经常见到。
构造函数
无已有的构造函数,一般起名为new开头。有些构造函数写成了方法,因此只需要写成new就行,eg:errors.New()会比errors.NewError()简洁。
组合
声明
可以通过结构体实现组合。
type location struct {
x float64
y float64
}
type temperature struct {
celcius float64
}
type info struct {
location location
temp temperature
}嵌入
可以忽略字段名,此时可以转发方法。
命名冲突
由于方法可以转发,会造成命名冲突(原结构体方法和内含结构体的方法),如果直接调用,优先会调用自身的方法。
接口(interface)
声明
列举了类型必须满足的一组方法。感觉和rust的一样,目的是为了确保可以直接调用某个方法。为了复用,通常会把接口声明为类型。接口名称通常以er结尾。将其作为函数参数,可以使得函数仅关注于某个方法,而非整个结构体。
type hzaer interface {
why() int
where() string
}Go标准库有很多只有单个方法的接口。鼓励组合而不是继承。
指针
声明
&:取址,*:取值,但是无法获得字符串、数值、布尔字面值的地址。调用对象指针方法时,可以不用加*
函数
由于函数传参都是副本,所以传指针可以修改原值。通常来说,方法的接受者一般都是以指针进行传递的。
内部指针
指针可以获得结构体的内存地址,还可以获得结构体内指定字段的内存地址。
隐式指针
一些内置的集合类型暗中使用指针,例如Map(前面提到过map赋值时不会进行复制) slice也是,但是slice有显式指针,其作用为修改slice本身,包括长度、容量和起始的偏移量。
nil
概念
nil可以导致panic,例如解引用nil。注意:nil仍然能调用方法。
nil&函数
变量为声明为函数时,默认为nil。
nil&slice
slice在声明之后没有使用make或者复合字面值,会导致它的值为nil。但是len、cap、append函数都可以处理nil。
nil&map
变量声明为map时,默认为nil。
nil&interface
变量声明为interface时,零值为nil。对于一个未被赋值的接口,其接口和值都是nil,并且变量本身也等于nil。但是只有接口的类型和值都为nil,该接口类型变量才等于nil。
错误
定义
一般来说,函数返回值最后都会返回一个err,如果没有发生错误,则err为nil。惯例:错误以Err开头。
defer关键字
使用defer关键字可以确保在函数返回前一定执行的动作,例如释放资源。即使发生了panic,也会在函数返回前执行defer的动作。
自定义错误类型
error类型是一个内置接口,任何类型只要返回string的Error()方法就满足了这个接口。自定义错误以Error结尾。非常重要
类型断言
可以使用类型断言把接口类型转化为底层具体类型,例如err.(SudokuError)。可以从一个接口类型转换为另一个接口类型。
错误封装
可以使用fmt.Errorf对错误进行封装(套娃)。
firstErr := errors.New("this is the first error")
secondErr := fmt.Errorf("this is the second error, it include the first error: %w", firstErr)
thirdErr := fmt.Errorf("this is the third error, it include the second error: %w", secondErr)
// 输出各个错误
fmt.Printf("%+v\n", firstErr) // this is the first error
fmt.Printf("%+v\n", secondErr) // this is the second error, it include the first error: this is the first error
fmt.Printf("%+v\n", thirdErr) // this is the third error, it include the second error: this is the second error, it include the first error: this is the first error可以使用errors.Unwrap对错误进行解封。
errors.Is
errors.Is 方法判断被包装的 error 是否是包含指定错误,与直接使用 == 判断不同,Is 方法可以用于判断错误中是否包含指定的错误。Is 函数签名为:func Is(err, target error) bool,第一个参数为需要被判断的函数,第二个参数为目标错误,返回布尔类型变量表示是否包含指定错误。
errors.As
理解 As 方法首先需要理解 error 的定义,go 中 error 实际上就是一个包含 Error 方法的接口,只要实现了 Error 方法都可以作为 error。As 函数的作用就是从错误中获取第一个指定类型的错误。需要注意一点:实际上As函数是在使用reflect包对两个参数的类型进行比较,其中第二个参数是第一个参数类型的指针类型。
panic
运行时崩溃。可以创建panic:panic("")。可以使用recover函数避免,比如放在defer里面处理panic。
goroutine
定义
非常的重要。
goroutine与其他语言的协程、线程、进程都有相似之处,但是不是完全一样。
- 创建效率非常高
- 能直截了当的协同多个并发操作
- 使用goroutine可以快速执行多个并发任务
goroutine看似在同时进行,但是由于计算机处理单元有限,实际上是使用分时技术,因此各goroutine的执行顺序是随机的。
channel
定义
可以在多个goroutine之间安全的传递值。使用make函数可以指定传输数据的类型。
c := make(chan int)
//向通道发送值
c <- 99
//从通道接受值
a := <- c只能使用<-进行传递和接受值。
time.After
该函数返回一个通道,在指定时间后会接收到一个值(发送方为go运行时的一部分)
使用select处理多个通道
select和switch有点类似,每个case都持有一个通道,select会等待某个分支就绪再执行。
c := make(chan int)
timeout := time.After(2 * time.Second)
select {
case a := <-c:
fmt.Println(a)
case <-timeout:
fmt.Println("yeyeye")
return
}select处理不当时会永久等下去。
nil通道
如果不使用make初始化通道,那么通道变量的值为nil。可以向nil通道发送或接收,不会panic但是会永久堵塞。close
阻塞&死锁
goroutine一直等待通道消息即为被阻塞。如果永久被阻塞则称为死锁,这样的程序会崩溃或者挂起。
close函数
可以通过close函数关闭通道,尝试读取被关闭的通道会获取与通道类型对应的零值。可以通过v,ok := <- c中的ok为false即为通道关闭了。
常用方式
可以使用range关键字读取通道直至其被关闭为止。
for elem := range queue {
fmt.Println(elem)
}Timer & Ticker
感觉有点像js的setTimeout和setInterval。两者在触发的时候都可以在chan类型的timer.C和ticker.C中获取到信号。可以用timer.Stop()和ticker.Stop()提前停止计时。Timer是定时触发,Ticker是间断触发。
// 创建一个2秒后触发的定时器
timer := time.NewTimer(2 * time.Second)
// <-timer.C 会阻塞当前 Goroutine,直到定时器触发
<-timer.C重要函数
- timer.Stop(): 提前停止定时器。如果定时器还没触发,它会停止并返回 true。如果已经触发或已被停止,返回 false。这对于取消一个超时操作非常有用。
- timer.Reset(d time.Duration): 重置定时器的触发时间。如果你需要在一个循环中重复使用定时器,用 Reset 会比每次都创建一个新的 NewTimer 更高效。
ticker := time.NewTicker(1 * time.Second)作为函数参数
当使用 channels 作为函数参数时,可以指定通道是仅用于发送还是接收值。有利于程序性能。
func ping(pings chan<- string, msg string) {
pings <- msg
}
func pong(pings <-chan string, pongs chan<- string) {
msg := <-pings
pongs <- msg
}WaitGroup
要等待多个 goroutine 完成,我们可以使用 Wait Group。WaitGroup会等待一组并发执行的 Goroutine 全部完成。
sync.WaitGroup 的三个核心方法
- Add(delta int)
- 作用:增加 WaitGroup 的内部计数器。delta 可以是正数或负数,但通常我们用它来增加计数。
- 用法:在启动一个 Goroutine 之前,调用 wg.Add(1),表示有一个新的任务需要等待。
- Done()
- 作用:将 WaitGroup 的内部计数器减 1。它实际上是 wg.Add(-1) 的一个别名,更具可读性。
- 用法:在一个 Goroutine 完成其工作后,调用 wg.Done() 来通知 WaitGroup:“一个任务已经完成了”。通常,我们会使用 defer wg.Done() 来确保即使 Goroutine 发生 panic,也能正确地减少计数。
- Wait()
- 作用:阻塞调用 Wait() 的那个 Goroutine,直到 WaitGroup 的内部计数器减少到 0。
- 用法:通常在主 Goroutine 中调用,用来等待所有通过 Add 注册的并发任务全部完成。
func worker(id int) {
fmt.Printf("Worker %d starting\n", id)
time.Sleep(time.Second)
fmt.Printf("Worker %d done\n", id)
}
var wg sync.WaitGroup
for i := 1; i <= 5; i++ {
wg.Add(1)
//每次激活想要被等待完成的goroutine之前,先调用Add(),用来设置或添加要等待完成的goroutine数量
go func() {
defer wg.Done()
//每次需要等待的goroutine在真正完成之前,应该调用该方法来人为表示goroutine完成了,该方法会对等待计数器减1
worker(i)
}()
}
wg.Wait()
//在等待计数器减为0之前,Wait()会一直阻塞当前的goroutine并发状态
共享值&竞争条件
互斥锁(Go的)
mutex = mutual exclusive,并未内置在go中,位于"sync"包内,有lock()和unlock()方法。
type Visited struct {
mu sync.Mutex
visited map[string]int
}
// 使用
v.mu.Lock()
// 确保释放
defer v.mu.Unlock()工作进程
一般会写成for循环加select。
泛型
func SlicesIndex[S ~[]E, E comparable](s S, v E) int {
for i := range s {
if v == s[i] {
return i
}
}
return -1
}泛型的用法如上。comparable类型包括:booleans, numbers, strings, pointers, channels, arrays of comparable types, structs whose fields are all comparable types。
调用的时候可以指定S和E的类型,也可以不指定,编译器会自动替我们去判断类型。
// 显示指定类型
_ = SlicesIndex[[]string, string](s, "zoo")注意区分
- Comparable:可以使用 == 和 != 比较,非黑即白
- Ordered:可以使用 > >= < <= 做大小比较,有明确的大小概念
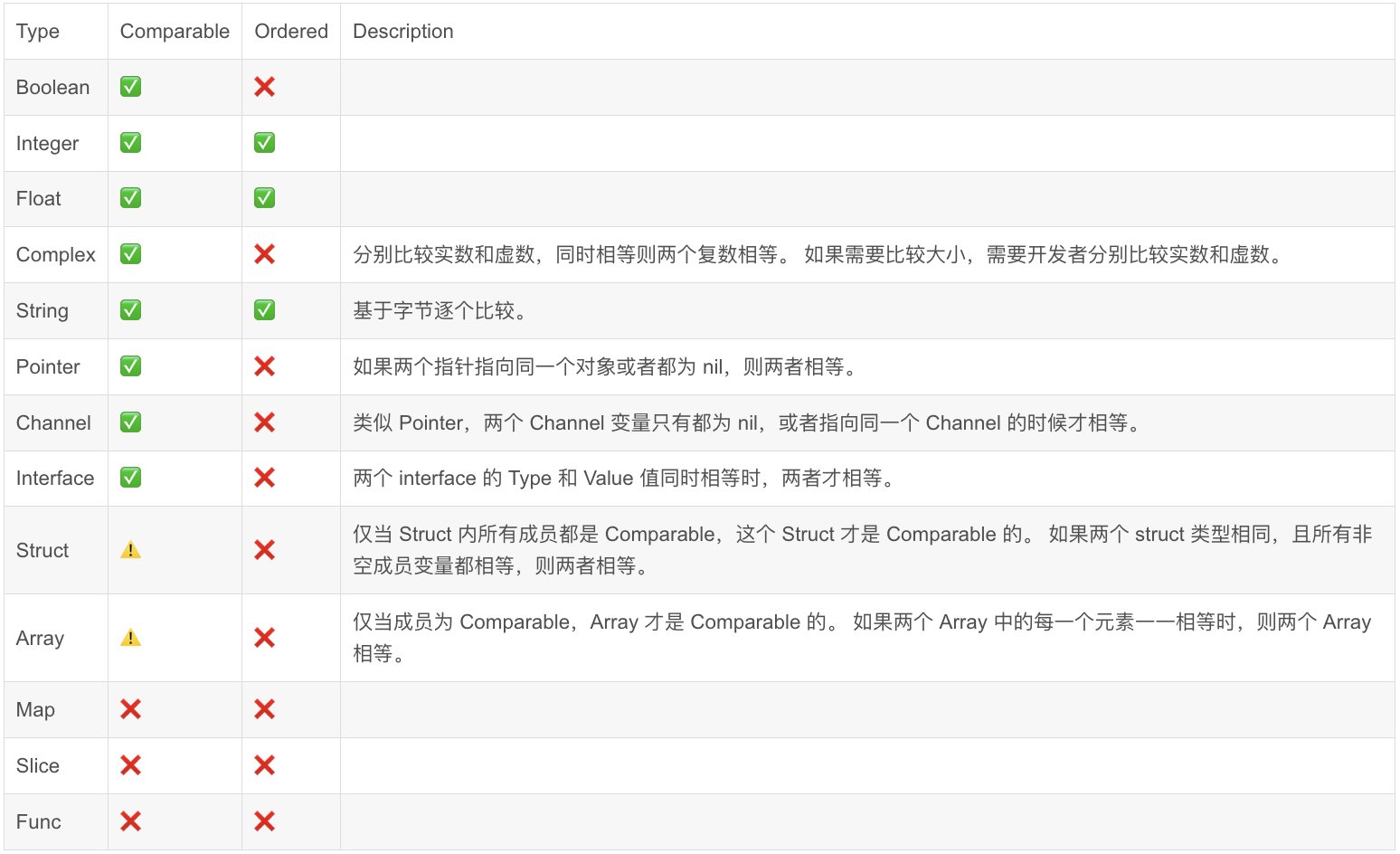 可以看到,go有
可以看到,go有complex类型,即复数类型,我都惊了。
迭代器
1.23版本更新的。实际上是指符合以下三种函数签名之一的函数:
func(yield func() bool)
func(yield func(V) bool)
func(yield func(K, V) bool)就是函数的参数为函数,通过yield函数返回的bool决定是否继续迭代。例如:
func Backward[E any](s []E) func(yield func(int, E) bool) {
return func(yield func(int, E) bool) {
for i := len(s) - 1; i >= 0; i-- {
if !yield(i, s[i]) {
return
}
}
}
}可以看出,我们要不断地迭代这个函数,不断获取值,而1.23的go开始支持遍历函数(挺离谱的功能),这个函数必须实现迭代器。
func main() {
s := []string{"程序员", "陈明勇"}
for i, v := range Backward(s) {
fmt.Println(i, v)
}
}挺牛掰。go还推出了iter包为了简化这一过程。该包定义了两种迭代器类型,分别是 Seq 和 Seq2,用于处理不同的迭代场景。
package iter
type Seq[V any] func(yield func(V) bool)
// Seq 是一个泛型类型的函数,接收一个 yield 函数作为参数。它推出单个元素,例如切片的索引或映射中的键。yield 函数返回 bool,决定是否继续迭代。
type Seq2[K, V any] func(yield func(K, V) bool)
// Seq2 是一个泛型类型的函数,接收一个 yield 函数,推送一对元素,例如切片中的索引和值,或者映射中的键值对。yield 函数同样返回 bool,以决定是否继续迭代。推拉迭代器
推迭代器将容器中的每个值主动推送到 yield 函数中。在 Go 语言中,我们可以通过 for-range 循环直接接收被推送的值。上面是推迭代器
与此相反,拉迭代器则是由调用方主动请求数据。每次调用拉迭代器时,它从容器中拉出下一个值并返回。虽然 for/range 语句不直接支持拉迭代器,但通过普通的 for 循环可以轻松实现对拉迭代器的迭代。
感觉拉迭代器更加主动,我问你你再给,相对于推迭代器通过yield的bool去判断迭代停止更灵活。iter 包提供了 Pull 函数,该函数接收一个标准(推)迭代器类型的参数,返回两个参数,第一个参数是拉迭代器,第二个参数是停止函数。当我们不再需要拉取元素的时候,调用停止函数即可。