
GO-knowledge
前记
用来记录一些go的进阶知识点 要准备面试了
常用的一些函数
- 统计字符串长度: len(str)
- 字符串遍历: []rune(str)
- 字符串转整数: strconv.Atoi("12")
- 整数转字符串: strconv.Itoa(12)
- 字符串转[]byte: var bytes = []byte("hello")
- []byte转字符串: var str = string([]byte{98,97})
- 查找子串是否在指定的字符串中: strings.Contains("seafood","foo") //true
- 统计一个字符串有几个指定的子串: strings.Count("ceheese", "e") //4
- 不区分大小写的字符串比较: strings.EqualFold("abc","Abc") //true
- 返回子串在字符串第一次出现的 index 值,如果没有返回-1: strings.Index("NLT_abc", "abc") //4
- 返回子串在字符串最后一次出现的 index 值,如果没有返回-1: strings.LastIndex("NLT_abc", "abc") //4
- 将指定的子串替换成另外一个子串: strings.Replace("go go hello", "go", "go 语言", n) n 可以指定你希望替换几个, 如果 n=-1 表示全部替换。将"go go hello"中的所有的n个"go"替换为"go语言"。
- 按照指定的某个字符,为分割标识,将一个字符串拆分成字符串数组:strings.Split("hello,world,ok", ",")
- 按照指定的某个字符为连接符,将一个字符串数组合并成字符串:strings.Join([]string{"hello","world","ok"}, ",")
- 将字符串的字母进行大小写的转换: strings.ToLower("Go") // go
- 将字符串的字母进行大小写的转换: strings.ToUpper("Go") // GO
- 将字符串左右两边的空格去掉: strings.TrimSpace(" tn a lone gopher ntrn ")
- 将字符串左右两边指定的字符去掉: strings.Trim("! hello! ", " !") // ["hello"] //将左右两边 !和 " "去掉
- 判断字符串是否以指定的字符串开头: strings.HasPrefix("ftp://192.168.10.1", "ftp") //true
- copy函数,将第二个slice里的元素拷贝到第一个slice里,拷贝的长度为两个slice中长度较小的长度值,不支持数组:
s1 := []int{1,2,3}
s2 := []int{4,5,6,7,8,9}
// s1长度比s2长度短,以len(s1)=3的长度复制
// 所以会将4,5,6覆盖掉1,2,3
// 所以下面s1打印出来为[4, 5, 6]
// copy函数会返回复制的长度
n := copy(s1, s2)- go在1.21版本开始内置了max、min函数以及clear函数
- clear函数
该函数接收一个参数 t,用于清空变量 t (类型为 slice 或 map) 中的元素。
* 如果传递的是切片类型变量,则会将切片的所有元素赋值为该切片类型的零值;
* 如果传递的是 map 类型变量,则会清空map 类型变量的元素;
* 如果传递的是自定义泛型类型(例如 type MySlice[T any] []T),则类型集中所有类型必须是 slice 或 map。math库
有一些比较常用的函数
- math.Abs()
- math.MaxInt / math.MinInt 整数的无穷大和负无穷大
- math.Inf(1) / math.Inf(-1) 浮点数的无穷大和负无穷大
sort函数 已经被取代,详情看slices包
内置的切片排序包。直接改变原数组。
- sort.Ints() //传入Int数组
- sort.Strings() //传入String数组
- sort.Float64s() //传入float64数组
- sort.Slice() //传入两个参数:第一个为需要排序的数据,第二个为对元素的回调函数,感觉和js的reduce函数很像
- sort.Stable() //稳定排序
//从大到小排序
sort.Slice(tmp,func(i,j int){ //tmp是要排序的切片
return tmp[i]<tmp[j]
})注意
由于没有自带的从大到小排序,因此可以使用slice自定义排序方式
- sort.Sort(sort.Reverse(sort.IntSlice(nums))) //将数组从大到校排序
sort.IntSlice(nums) 将普通的 []int 切片 nums 转换为 sort.IntSlice 类型
sort.IntSlice 是一个实现了 sort.Interface 接口的类型(包含 Len(), Less(i, j int) bool, Swap(i, j int) 方法)
默认情况下,IntSlice 的 Less() 方法定义为 p[i] < p[j],即按升序排序
sort.Reverse(...) 接收一个实现了 sort.Interface 的类型(这里是 IntSlice)
返回一个新的 reverseInterface 类型,它包装了原始接口
关键变化是反转了 Less() 方法的逻辑:
源码分析:
// reverse 是一个实现了 sort.Interface 的结构体
type reverse struct {
Interface // 嵌入原始 Interface
}
// 重写 Less 方法实现逻辑反转
func (r reverse) Less(i, j int) bool {
return r.Interface.Less(j, i) // 关键点:调换参数位置
}
// Reverse 返回一个包装后的 Interface
func Reverse(data Interface) Interface {
return &reverse{data}
}- sort.Sort(...) 对实现了 sort.Interface 的数据进行实际排序,由于 Less() 方法已被反转,结果就是降序排列
我的理解
sort包使用的是快速排序,针对sort.Interface这个类型进行排序,这个接口有Len(),Less(),Swap()三个方法,sort.Reverse使得该类型中的Less结果倒置,然后再进行排序,进而达到想要的从大到小的效果。
slices包
Go 1.21引入了新的slices包,提供了更丰富的切片操作函数,且不修改原切片,而是返回一个新的切片。
1. 元素位置与计数
| 函数 | 用法示例 | 说明 |
|---|---|---|
Index | idx := slices.Index(s, target) | 返回目标元素第一次出现的索引,未找到返回 -1。 |
LastIndex | idx := slices.LastIndex(s, target) | 返回目标元素最后一次出现的索引。 |
IndexFunc | idx := slices.IndexFunc(s, f) | 返回第一个满足函数 f 条件的元素索引。 |
BinarySearch | i, found := slices.BinarySearch(s, target) | 二分查找(要求切片有序)。返回索引和是否找到。 |
2. 逻辑判断
| 函数 | 用法示例 | 说明 |
|---|---|---|
Contains | ok := slices.Contains(s, target) | 判断切片中是否包含目标元素。 |
ContainsFunc | ok := slices.ContainsFunc(s, f) | 判断切片中是否存在满足函数 f 条件的元素。 |
Equal | ok := slices.Equal(s1, s2) | 判断两个切片是否等长且元素一一对应相等。 |
EqualFunc | ok := slices.EqualFunc(s1, s2, f) | 使用自定义比较函数 f 判断两个切片是否相等。 |
IsSorted | ok := slices.IsSorted(s) | 判断切片是否已按升序排列。 |
IsSortedFunc | ok := slices.IsSortedFunc(s, f) | 使用自定义比较函数判断切片是否有序。 |
3. 切片修改与重构
| 函数 | 用法示例 | 说明 |
|---|---|---|
Delete | s = slices.Delete(s, i, j) | 删除索引 [i, j) 范围内的元素,返回新切片。 |
DeleteFunc | s = slices.DeleteFunc(s, f) | 删除所有满足函数 f 条件的元素。 |
Replace | s = slices.Replace(s, i, j, v...) | 将 [i, j) 范围内的元素替换为指定的一组新元素。 |
Insert | s = slices.Insert(s, i, v...) | 在索引 i 处插入一组元素并返回新切片。 |
Compact | s = slices.Compact(s) | 将连续重复的元素压缩为一个(类似于 uniq)。 |
CompactFunc | s = slices.CompactFunc(s, f) | 使用自定义相等判断函数压缩连续重复元素。 |
Grow | s = slices.Grow(s, n) | 增加切片的容量,确保至少能再容纳 n 个元素。 |
Clip | s = slices.Clip(s) | 移除切片多余的容量,使 cap(s) == len(s)。 |
4. 排序与极值
| 函数 | 用法示例 | 说明 |
|---|---|---|
Sort | slices.Sort(s) | 对切片进行升序排序。 |
SortFunc | slices.SortFunc(s, f) | 使用自定义比较函数(返回 int)进行排序。 |
SortStableFunc | slices.SortStableFunc(s, f) | 稳定排序,保证相等元素的原始相对位置不变。 |
Min | m := slices.Min(s) | 返回切片中的最小值(切片不能为空)。 |
Max | m := slices.Max(s) | 返回切片中的最大值(切片不能为空)。 |
MinFunc | m := slices.MinFunc(s, f) | 使用自定义比较逻辑返回最小值。 |
5. 迭代器操作 (Go 1.23+)
| 函数 | 用法示例 | 说明 |
|---|---|---|
Collect | s := slices.Collect(iter) | 将迭代器中的所有元素收集到一个新切片中。 |
Values | for v := range slices.Values(s) | 返回一个仅包含切片元素的迭代器。 |
All | for i, v := range slices.All(s) | 返回一个包含 (index, value) 的迭代器。 |
AppendSeq | s = slices.AppendSeq(s, iter) | 将迭代器中的元素追加到现有切片。 |
unicode包
Go 1.21引入了新的unicode包,提供了更丰富的Unicode字符处理函数。
- unicode.IsDigit
- unicode.IsLetter
- unicode.IsSpace
- unicode.IsUpper
- unicode.IsLower
- unicode.ToUpper
- unicode.ToLower
container包
Go 1.21引入了新的container包,提供了更丰富的容器数据结构和相关函数。
container/heap
需要满足以下条件才能使用heap包:
import (
"container/heap"
"fmt"
)
// 1. 定义一个类型,通常是 slice
type IntHeap []int
// 2. 实现 sort.Interface 的三个方法
func (h IntHeap) Len() int { return len(h) }
func (h IntHeap) Less(i, j int) bool { return h[i] < h[j] } // < 是小顶堆,> 是大顶堆
func (h IntHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }
// 3. 实现 heap.Interface 的 Push 和 Pop
// 注意:必须使用指针接收者 (*h),因为要修改切片的长度(append/reslice)
func (h *IntHeap) Push(x any) {
// 这里只是把元素放到 slice 的末尾
// 真正的“上浮”逻辑由 heap.Push 调用库函数处理
*h = append(*h, x.(int))
}
func (h *IntHeap) Pop() any {
// 这里只是把 slice 末尾的元素拿出来
// 真正的“下沉”和交换逻辑由 heap.Pop 处理完后再调用这个
old := *h
n := len(old)
x := old[n-1]
*h = old[0 : n-1]
return x
}然后开始建堆:
func main() {
nums := []int{3, 1, 4, 1, 5}
// 必须转成我们定义的类型
h := IntHeap(nums)
// 【关键步骤】建堆
// 时间复杂度:O(N)
// 这一步会调整切片元素的顺序,使其满足堆的性质
heap.Init(&h)
fmt.Println("堆化后:", h) // 输出: [1 1 4 3 5] (具体顺序可能不同,但根节点肯定是最小的)
}使用的时候,如下:
- 入堆:heap.Push(&h, 3)
- 它会先调用你的 Push 方法把元素放到末尾。
- 然后自动执行 up(上浮)操作,把元素移到正确位置。
- 时间复杂度:
- 出堆:x := heap.Pop(&h)
- 它会先把堆顶元素(最小值)和末尾元素交换。
- 然后执行 down(下沉)操作修复堆。
- 最后调用你的 Pop 方法把原来的堆顶(现在在末尾)拿出来返回。
- 时间复杂度:
查看堆顶元素:h[0] // 直接访问切片的第一个元素就是堆顶
更新堆中某个元素的值后,需要调用
heap.Fix(&h, index)来重新调整堆结构。
(*h)[3].Priority = 100 // 修改索引 3 的优先级
heap.Fix(h, 3) // 告诉堆:索引 3 变了,请调整它的位置- 可以调用
heap.Remove删除任意位置的元素。
heap.Remove(&h, index) // 删除索引 index 的元素,并调整堆container/list
Go 1.21引入了新的container/list包,提供了更丰富的双向链表操作函数。插入和删除操作是 ,不需要像 Slice 那样扩容或移动内存。常用方法:PushFront, PushBack, InsertBefore, InsertAfter, Remove, MoveToFront。
package main
import (
"container/list"
"fmt"
)
func main() {
// 创建一个新的双向链表
l := list.New()
// 插入元素 (O(1))
e4 := l.PushBack(4)
e1 := l.PushFront(1)
// 在 e4 之前插入 3
l.InsertBefore(3, e4)
// 遍历链表 (这是最麻烦的地方)
for e := l.Front(); e != nil; e = e.Next() {
// 注意:Value 是 interface{} 类型,使用时通常需要断言
fmt.Println(e.Value)
}
// 输出: 1 3 4
}container/ring
Go 1.21引入了新的container/ring包,提供了更丰富的循环(环形)链表操作函数。大小通常是固定的(虽然也可以动态链接),非常适合做“轮询”或“保存最近 N 个记录”。常用方法:Next, Prev, Move(n), Link, Unlink。
package main
import (
"container/ring"
"fmt"
)
func main() {
// 创建一个大小为 3 的环
r := ring.New(3)
// 初始化环中的值
for i := 1; i <= 3; i++ {
r.Value = i
r = r.Next()
}
// 遍历环 (需要用 Do 方法,或者手动循环 N 次)
r.Do(func(p interface{}) {
fmt.Printf("%d ", p.(int))
})
// 输出: 1 2 3
fmt.Println()
// 移动指针 (比如向后移动 1 位)
r = r.Move(1)
fmt.Println("当前指针值:", r.Value) // 输出: 2
}Iterators
Go 1.21引入了新的迭代器接口和相关函数,提供了更丰富的迭代器操作功能。迭代器是一种抽象的概念,表示一个可以逐个访问元素的数据结构。Go 的迭代器接口定义如下:
type Iterator[T any] interface {
Next() (T, bool) // 返回下一个元素和是否还有更多元素
}Go 的标准库新增了一个极小的包 iter,里面只定义了两个核心类型:
- iter.Seq[V]:产生单个值的序列(类似遍历切片时只取值)。
- 底层签名:func(yield func(V) bool)
- iter.Seq2[K, V]:产生键值对的序列(类似遍历 map 或带索引遍历切片)。
- 底层签名:func(yield func(K, V) bool)
maps包
Go 1.21引入了新的maps包,提供了更丰富的 map 操作函数。
- maps.Copy
dst := map[string]int{"a": 1, "b": 2}
src := map[string]int{"b": 3, "c": 4}
maps.Copy(dst, src)
// 结果 dst: map[a:1 b:3 c:4]- maps.Clone
// maps.Clone
original := map[string]int{"apple": 10, "banana": 20}
cloned := maps.Clone(original)
cloned["apple"] = 99
fmt.Println(original["apple"]) // 依然是 10,不受克隆体影响
// !!!它执行的是浅拷贝。如果 Map 的值是指针,克隆后的指针依然指向同一个地址。- maps.Equal 和 maps.EqualFunc
// maps.Equal
m1 := map[string]int{"a": 1, "b": 2}
m2 := map[string]int{"b": 2, "a": 1}
fmt.Println(maps.Equal(m1, m2)) // 输出 true
// maps.EqualFunc
m1 := map[string]int{"a": 1, "b": 2}
m2 := map[string]int{"b": 3, "a": 1}
equalFunc := func(v1, v2 int) bool {
return v1%2 == v2%2 // 只比较值的奇偶性
}
fmt.Println(maps.EqualFunc(m1, m2, equalFunc)) // 输出 true,因为 1%2 == 1%2 和 2%2 == 3%2- maps.DeleteFunc
// maps.DeleteFunc
m := map[string]int{"a": 1, "b": 2, "c": 3}
deleteFunc := func(key string, value int) bool {
return value%2 == 0 // 删除值为偶数的键值对
}
maps.DeleteFunc(m, deleteFunc)- maps.Keys 和 maps.Values
// maps.Keys
m := map[string]int{"a": 1, "b": 2, "c": 3}
keys := maps.Keys(m)
values := maps.Values(m)
// 一定要注意!!!这里返回的 keys 和 values 是迭代器,不能直接使用,需要转换成切片或者遍历使用。
for k := range keys {
// 并且!!!对于迭代器的遍历,range是不会再给出index作为第一个参数的,所以只能拿到value
fmt.Println(k) // 输出 a, b, c
}
// 或者
fmt.Println(slices.Collect(keys)) // 输出 [a b c]cmp包
这个包非常的小,包含的函数如下:
- cmp.Compare
定义为func Compare[T Ordered](x, y T) int,用于比较两个值的大小,返回一个整数表示比较结果:
- 如果 x < y,返回 -1
- 如果 x == y,返回 0
- 如果 x > y,返回 1
- cmp.Less
定义为func Less[T Ordered](x, y T) bool,用于判断 x 是否小于 y,返回一个布尔值。
cmp.Ordered
你会发现 cmp 的泛型约束是 Ordered。这其实是 cmp 包定义的一个接口集,它涵盖了所有支持 <、> 运算符的内置类型:
- 所有整数(int, int64, uint 等)
- 所有浮点数(float32, float64)
- 字符串(string)
new函数和make函数
new用来分配内存,主要用来分配值类型,比如 int/float32/struct。返回的是指针。make也用来分配内存,主要用来分配引用类型,比如 channel/map/slice。返回引用类型本身。
区别:
- new 返回指针,make 返回引用类型
- new 没有参数,make 需要指定类型
- make 返回初始化后可以直接使用的对象,new 返回还需要初始化的指针
- make 只用于 slice、map、channel 等内置引用类型,new 可用于任意类型
append函数
非常重要的函数
append操作数组,可以追加元素、切片,删除元素
- 追加元素
slice = append(slice,elem1,elem2)append括号内,第一个参数slice后可以加多个参数。
- 追加切片
slice = append(slice,anotherSlice...)通过...拆分切片
- 删除元素
s = append( s[:index], s[index+1:] )但是比较低效,下面的方法会更为高效
func DeleteSlice3(a []int, elem int) []int {
j := 0
for _, v := range a {
if v != elem {
a[j] = v
j++
}
}
return a[:j]
}装饰器模式
// 装饰器模式
type Handler func(http.ResponseWriter, *http.Request)
// 等于是一个中间键,将handler包起来了
func Logger(handler Handler) Handler {
return func(w http.ResponseWriter, r *http.Request) {
start_time := time.Now()
handler(w, r)
log.Printf("url:%v,duration:%v", r.URL, time.Since(start_time))
}
}一些面试问题
- make 和 new 的区别﹖
- 了解过golang的内存管理吗?
答案
Go (Golang) 的内存管理是一个高度优化的系统,它旨在实现高并发性能、低延迟的垃圾回收 (GC) 和高效的内存分配。
其核心可以分为三个主要部分:
- 栈 (Stack) 与堆 (Heap) 的划分:Go 编译器通过“逃逸分析”来决定变量是分配在栈上还是堆上。
- 高效的内存分配器:一个受 Google TCMalloc 启发的、为并发优化的分配器,用于管理堆内存。
- 并发垃圾回收 (GC):一个先进的三色标记-清除 (Tri-color Mark-Sweep) 收集器,它与你的程序并发运行,以实现极短的“Stop-The-World” (STW) 暂停时间。
1. 栈 (Stack) vs. 堆 (Heap)
Go 语言的内存分为两块主要区域:
栈 (Stack):
- 用途:用于存储函数内的局部变量(如
int,bool,以及未“逃逸”的结构体和指针)。 - 特点:每个 Goroutine 都有自己独立的、非常小的初始栈(通常仅 2KB)。
- 管理:由编译器自动管理。内存分配和释放非常快(只需移动栈顶指针),函数返回时其栈帧就自动销毁。栈上的内存不需要 GC。
- 用途:用于存储函数内的局部变量(如
堆 (Heap):
- 用途:用于存储动态分配的、生命周期更长的数据。所有 Goroutine 共享同一个堆。
- 特点:分配和释放的开销比栈高。
- 管理:由垃圾回收器 (GC) 自动管理。
什么是“逃逸分析” (Escape Analysis)?
在编译时,Go 编译器会进行一项关键分析,名叫“逃逸分析”。它会检查一个变量的生命周期,来决定它应该被分配在哪里。
不逃逸(分配在栈上):
- 如果一个变量(包括结构体)只在函数内部使用,并且在函数返回后不再被引用,它就会被分配在栈上。
- 例子:
func main() { x := 5 }
逃逸(分配在堆上):
- 如果编译器无法证明变量在函数返回后不被引用,该变量就会“逃逸”到堆上。
- 常见逃逸情况:
- 返回指针:
func foo() *int { x := 5; return &x }(变量x在函数返回后仍需被访问,因此x逃逸到堆上)。 - 被闭包引用:一个 goroutine 或
defer中的闭包函数引用了外部变量。 - 动态类型:
fmt.Println(a ...interface{})这种接口类型的参数,编译器不确定其具体类型,通常会分配在堆上。 - 大对象:一个非常大的局部变量,即使不返回,也可能被编译器决定放在堆上,以防栈溢出。
- 返回指针:
为什么这很重要? 分配在栈上几乎没有开销,而分配在堆上则会给 GC 带来压力。Go 程序员会尽量减少不必要的内存逃逸,以提高性能。
2. Go 的内存分配器 (TCMalloc-based)
Go 的分配器经过精心设计,以高效处理数万个 Goroutine 的并发内存请求,避免锁竞争。它采用分层结构:
mheap(全局堆):mheap是全局的,它向操作系统申请大块内存(称为 "Arenas",例如 64MB)。- 它负责将这些大内存块切分成更小的单元("Spans")。
- 当需要分配大对象(> 32KB)时,会直接从
mheap分配。
mcentral(中心缓存):mcentral按大小类别 (Size Class) 来组织内存。例如,有一个mcentral专门管理 16 字节的内存块,另一个专门管理 32 字节的内存块。- 它充当
mheap和mcache之间的“批发商”。
mcache(本地缓存):- 这是并发性能的关键。每个处理器 (P)(注意:不是 Goroutine)都有一个自己的
mcache。 - 当一个 Goroutine(运行在 P 上)需要分配小对象(≤ 32KB)时,它会无锁地从
mcache中获取。这非常快,因为没有并发冲突。
- 这是并发性能的关键。每个处理器 (P)(注意:不是 Goroutine)都有一个自己的
分配流程(小对象):
- Goroutine 需要内存。
- 它向其绑定的处理器 (P) 的
mcache请求。 mcache中有对应大小的空闲内存,直接返回。(最快的路径)mcache中没有了,它会向mcentral"批发"一批对应大小的 Spans。mcentral也没有了,它会向mheap请求一个更大的内存块,并将其切割成所需大小。mheap也没内存了,它会向操作系统申请一个新的 Arena。
3. Goroutine 的栈管理
与操作系统线程(通常有 1MB-8MB 的固定大栈)不同,Go 希望能同时运行成千上万个 Goroutine。
- 动态小栈:
- 每个 Goroutine 启动时只有一个 2KB 的小栈。
- 栈增长:Go 编译器会在函数调用前插入检查。如果发现当前栈空间不足以运行该函数,Go 运行时会分配一个新的、更大的栈(通常是原来的2倍),并将旧栈的数据完整地拷贝到新栈中,然后再执行函数调用。
- 栈收缩:在 GC 期间,如果 Go 发现一个 Goroutine 长时间处于空闲状态,并且其栈空间使用率很低,它会把该栈收缩(拷贝)回一个更小的栈,以释放内存。
4. 并发垃圾回收 (GC)
Go 的 GC 是其低延迟的关键。它是一个并发的三色标记-清除收集器,绝大部分工作都与你的程序代码并发执行,只会导致两次极短的 STW (Stop-The-World) 暂停。
GC 的四个阶段:
Mark Setup (STW - 标记准备):
- (暂停程序)
- 这是一个非常短暂的 STW 暂停(通常在 10-100 微秒)。
- 它的唯一任务是:开启“写屏障” (Write Barrier)。
- (恢复程序)
Marking (Concurrent - 并发标记):
- GC 开始并发地扫描。它从"根"对象(全局变量、Goroutine 栈上的变量)出发,查找所有可达的(仍在使用的)对象。
- 它使用三色抽象(白、灰、黑)来跟踪进度:
- 白色:潜在的垃圾(未被访问)。
- 灰色:已访问,但其引用的对象还未被扫描(待处理)。
- 黑色:已访问,且其引用的对象也已全部扫描(处理完毕)。
- GC 会占用约 25% 的 CPU 资源来执行这个扫描工作。
Mark Termination (STW - 标记终止):
- (暂停程序)
- 这是第二次 STW 暂停,也非常短暂。
- 它会关闭“写屏障”,并完成所有剩余的标记工作(处理在并发标记阶段中因竞争而遗漏的少量对象)。
- (恢复程序)
Sweeping (Concurrent - 并发清除):
- GC 开始并发地“清除”内存。
- 它遍历堆,将所有在标记阶段结束后仍为白色(不可达)的对象所占用的内存回收,以便下次分配时使用。
- 这个清除过程是“惰性”的,它在后台进行,并且在 Goroutine 申请新内存时也会触发局部的清除。
什么是“写屏障” (Write Barrier)?
“写屏障”是实现并发标记的核心技术。
- 问题:在 GC 并发标记(第2阶段)时,你的程序也在运行。如果你的程序执行了
A.ptr = B这样的指针赋值操作,会发生什么? - 危险:假设
A已经被 GC 扫描(是黑色),而B还没被扫描(是白色)。如果 GC 认为A已经处理完了,它就永远不会再去扫描A,因此也永远发现不了B。B就会被错误地当作垃圾(白色)回收掉,导致程序崩溃。 - 解决方案:写屏障是编译器在所有指针写入操作前插入的一小段代码。当
A.ptr = B发生时,如果A是黑色,B是白色,写屏障会强制将B标记为灰色,并放入待处理队列。 - 作用:写屏障确保了 GC 不会“丢失”任何在并发标记期间新建立的引用关系,保证了 GC 的正确性。
- 调用函数传入结构体时,应该传值还是指针﹖说出你的理由?
- 线程有几种模型?Goroutine的原理了解过吗,讲一下实现和优势?
- Goroutine什么时候会发生阻塞?
答案
Goroutine 的阻塞是指它暂停执行,等待某个条件达成。常见的阻塞情况有:
- Channel 操作:
- 从一个空的 channel 读取。
- 向一个满了的(有缓冲)或无接收者的(无缓冲)channel 发送。
- 锁操作: 调用 sync.Mutex 或 sync.RWMutex 的 Lock() 方法,而锁已被其他 Goroutine 持有。
- 同步等待: 调用 sync.WaitGroup 的 Wait() 方法,而计数器还未归零。
- 网络 I/O: 进行网络读写,等待数据返回或发送完成。
- 文件 I/O: 进行磁盘文件读写。
- 定时器: time.Sleep() 或 time.After()。
重要的是,当 Goroutine 因上述原因阻塞时,Go 调度器会将其置为等待状态,并让出其所在的线程去执行其他可运行的 Goroutine。
- PMG模型中Goroutine有哪几种状态?
答案
一个 Goroutine 在其生命周期中会经历几种状态,主要包括:
- _Gidle: 闲置状态,刚被分配,还未初始化。
- _Grunnable: 可运行状态,在 P 的本地队列中,等待被 M 执行。
- _Grunning: 运行状态,正在被 M 和 P 执行。
- _Gsyscall: 系统调用状态,正在执行一个阻塞的系统调用,此时 M 会与 P 分离。
- _Gwaiting: 等待状态,因 channel、锁等原因被阻塞,等待被唤醒。
- _Gdead: 死亡状态,已执行完毕,其栈空间可以被回收。
- 每个线程/协程占用多少内存知道吗?
答案
- Goroutine (协程): 初始栈空间非常小,在 Go 1.4 之后约为 2KB。它的栈是动态可伸缩的,如果需要更多空间,运行时会自动分配,最大可达 GB 级别。
- OS Thread (线程): 栈空间是固定的,且大得多。在 Linux 上通常是 2MB 或 8MB,在 Windows 上是 1MB。
这个巨大的差异解释了为什么可以轻松创建上百万个 Goroutine,但创建几千个线程就会耗尽系统资源。
- 如果Goroutine—直占用资源怎么办,PMG模型怎么解决的这个问题?
答案
这个问题指的是一个 Goroutine 长时间进行纯计算,不发生任何阻塞或函数调用,导致它霸占一个 P 和 M,使得 P 队列中的其他 Goroutine 无法得到执行。 Go 通过抢占式调度来解决这个问题。
从 Go 1.14 开始,引入了基于信号的异步抢占机制。
系统会有一个监控线程 sysmon。如果 sysmon 发现一个 Goroutine 在一个 P 上运行超过一个阈值(例如 10ms),它会向该 P 所在的 M 线程发送一个信号。M 线程接收到信号后,会中断当前正在执行的 Goroutine,将其重新放回 P 的可运行队列的队尾,然后从队列头部取下一个 Goroutine 来执行。
这样就保证了即使有“流氓” Goroutine,调度器也能保证公平性,让其他 Goroutine 有机会运行。
- 如果若干线程中一个线程OOM,会发生什么?如果是 Goroutine 呢?项目中出现过OOM吗,怎么解决的?
答案
- 线程 OOM: 内存是由进程管理的,线程共享进程的内存空间。如果一个线程的内存分配请求导致整个进程的可用内存耗尽,操作系统会终止整个进程,通常会发送 SIGKILL 信号。所以,一个线程 OOM 会导致整个程序崩溃。
- Goroutine OOM: Goroutine 不是操作系统层面的概念。它分配内存,实际上是它所在的进程在分配内存。因此,如果一个 Goroutine 的内存分配导致进程内存耗尽,结果和线程 OOM 完全一样:整个 Go 程序崩溃。
项目中出现 OOM 的解决办法:
原因: 通常是内存泄漏导致的,比如:
- Goroutine 泄露:Goroutine 因永久阻塞而无法退出,其栈空间无法回收。
- 全局变量(如 map)无限增长。
- 处理大数据时,一次性将所有数据读入内存。
解决方法:
- 定位问题: 使用 Go 的 pprof 工具是关键。通过 net/http/pprof 开启 HTTP 服务,访问 http://.../debug/pprof/heap 可以获取内存剖析文件。
- 分析工具: 使用 go tool pprof 命令分析 heap 文件,它可以图形化地展示哪些函数分配了最多的内存。
修复代码:
- 修复 Goroutine 泄露: 确保所有 Goroutine 都有明确的退出路径,比如使用 context 进行取消,或保证 channel 会被关闭。
- 处理大数据: 使用流式处理或分块处理,而不是一次性加载。
- 设置上限: 为缓存等全局结构设置大小上限和淘汰策略。
- 项目中错误处理是怎么做的?
- 如果若干个Goroutine,其中有一个panic,会发生什么?
答案
如果一个 Goroutine 发生了 panic,并且这个 panic 没有在该 Goroutine 内部被 recover 捕获,那么这个 panic 会导致整个 Go 程序崩溃退出。
panic 会终止当前 Goroutine,然后运行时会打印出 panic 信息和该 Goroutine 的调用栈,接着整个进程就会异常终止。其他所有正在运行的 Goroutine 都会被强制停止。
- defer可以捕获到其Goroutine的子Goroutine 的panic吗?
答案
不能。
defer, panic, 和 recover 的作用域严格限制在同一个 Goroutine 内部。一个 Goroutine 发生的 panic,只能被该 Goroutine 自己的 defer 函数中的 recover() 捕获。父 Goroutine 无法捕获由它启动的子 Goroutine 中发生的 panic。
正确做法:如果需要处理子 Goroutine 的 panic,必须在子 Goroutine 的代码中自己实现 defer recover(),然后通过 channel 将错误或 panic 信息传递回父 Goroutine。
- 开发用Gin框架吗?Gin怎么做参数校验?
答案
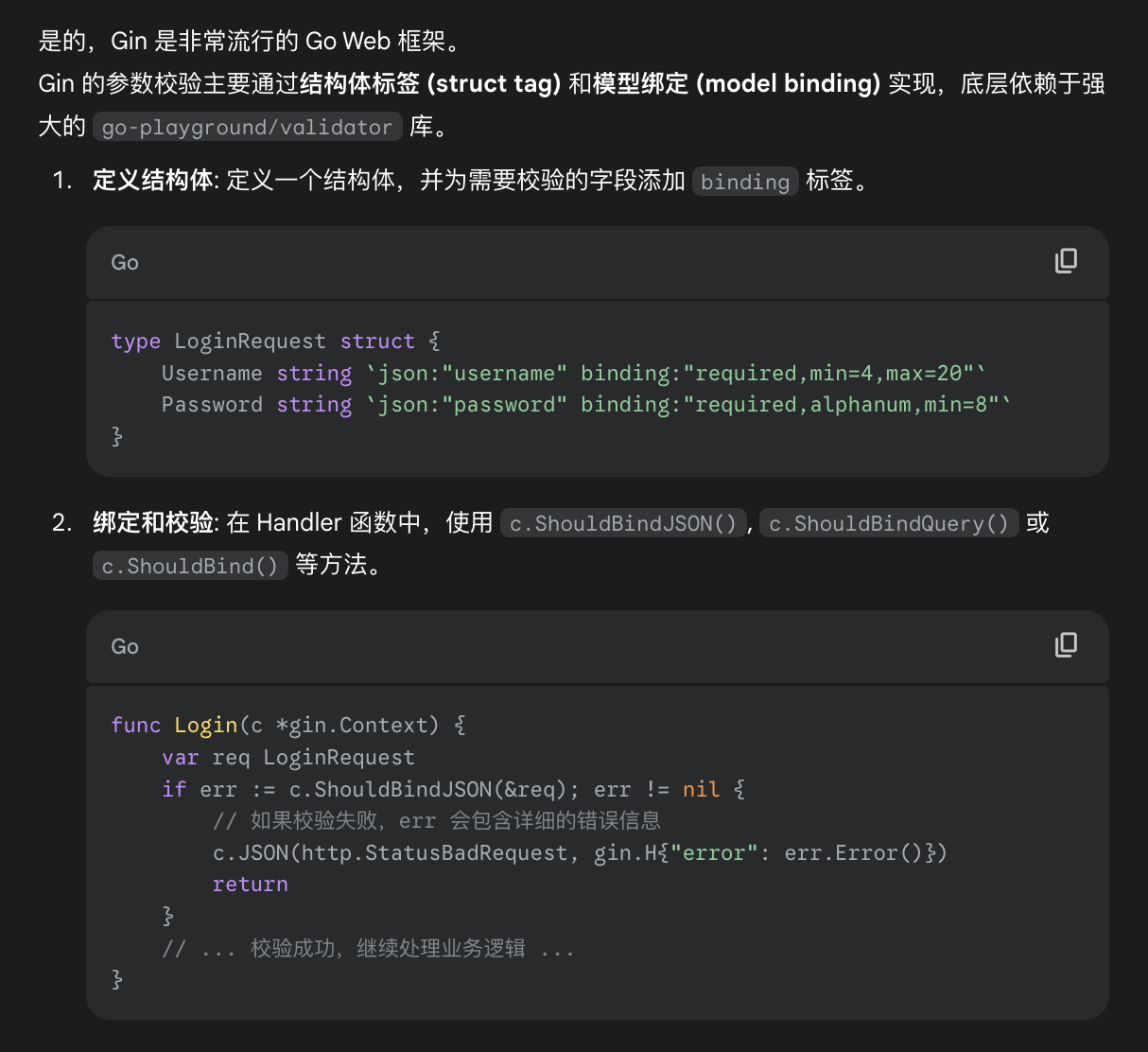
- 中间件使用过吗?怎么使用的。Gin的错误处理使用过吗?Gin中自定义校验规则知道怎么做吗?自定义校验器的返回值呢?
答案

- golang中解析tag是怎么实现的?反射原理是什么?通过反射调用函数
答案
1. 解析tag的实现
Go 中的结构体 tag(标签)是在编译时存储的元数据字符串。在运行时,我们必须使用反射 (reflect) 包来解析它。
实现步骤如下:
- 获取一个结构体变量的
reflect.Type。 - 遍历这个
Type的所有字段 (NumField())。 - 从每个
StructField字段中,访问其.Tag属性(类型为reflect.StructTag)。 StructTag类型有一个.Get("tagName")方法,用它来解析特定key的值。
示例代码:
package main
import (
"fmt"
"reflect"
)
type User struct {
Name string `json:"name" validate:"required"`
Age int `json:"age"`
}
func main() {
u := User{}
t := reflect.TypeOf(u) // 1. 获取 Type
// 2. 遍历字段
for i := 0; i < t.NumField(); i++ {
field := t.Field(i)
// 3. 访问 Tag
tag := field.Tag
// 4. 使用 Get 方法解析
fmt.Printf("字段: %s\n", field.Name)
fmt.Printf(" json tag: '%s'\n", tag.Get("json"))
fmt.Printf(" validate tag: '%s'\n", tag.Get("validate"))
}
}
// 输出:
// 字段: Name
// json tag: 'name'
// validate tag: 'required'
// 字段: Age
// json tag: 'age'
// validate tag: ''2. 反射原理
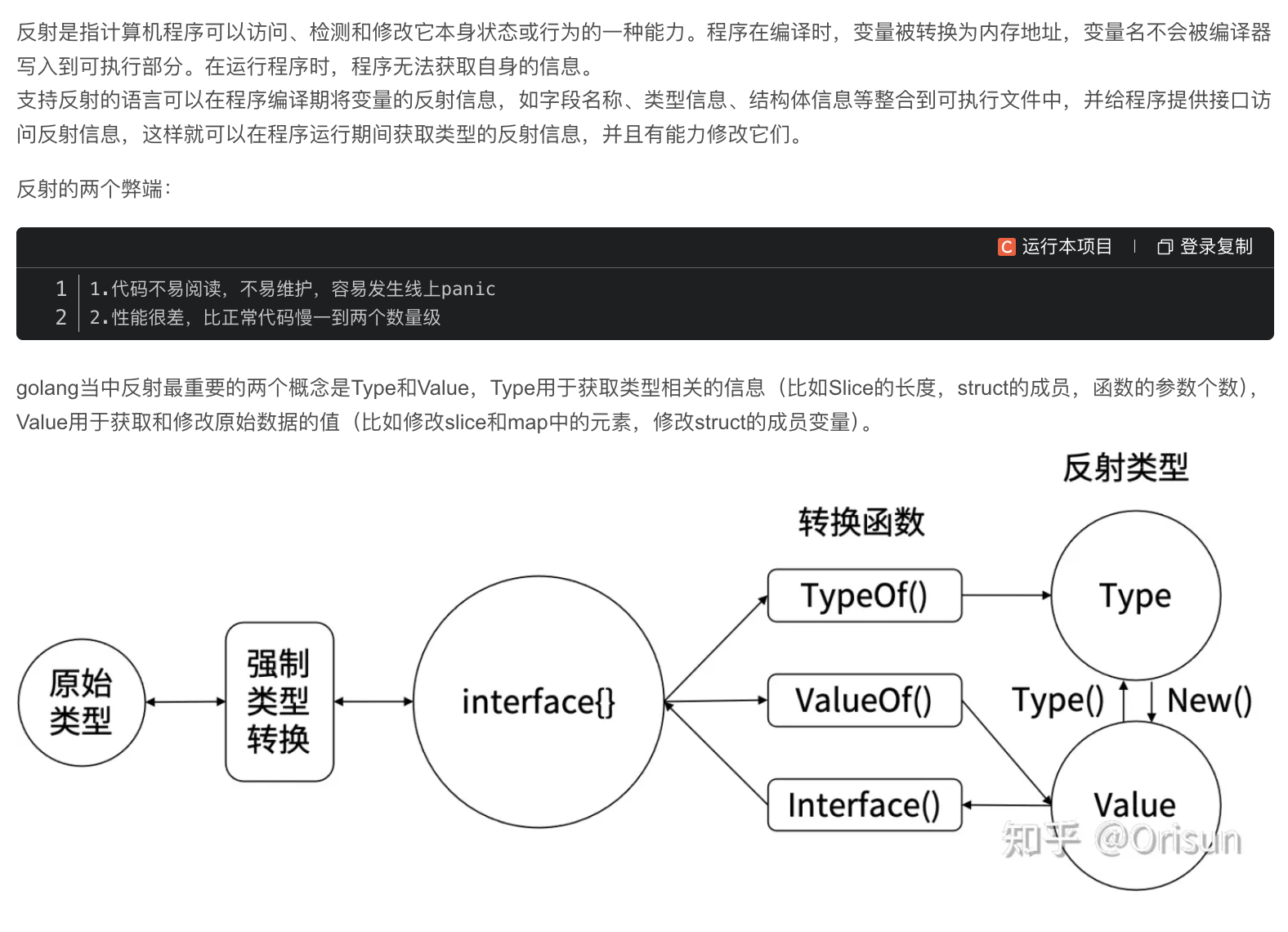
Go 的反射原理建立在“类型”和“接口”之上。
接口的内部结构: 在 Go 中,一个接口变量(如
interface{})内部存储着两部分信息:- 动态类型 (Dynamic Type):变量的实际类型(例如
int,*User)。 - 动态值 (Dynamic Value):变量的实际值(例如
5,0x...)。
- 动态类型 (Dynamic Type):变量的实际类型(例如
两大核心 API: 反射就是从
interface{}变量中提取上述两个信息。reflect.TypeOf(i interface{}): 获取变量的动态类型,返回一个reflect.Type。reflect.ValueOf(i interface{}): 获取变量的动态值,返回一个reflect.Value。
reflect.Value 是一个非常重要的数据结构,它持有了变量的值,并提供了检查(如 .Kind())、获取(如 .Int(), .String())甚至修改这个值的方法(如 .SetInt(), .SetString())。
注意: 要想通过反射修改一个变量,你必须传递这个变量的指针给 reflect.ValueOf(),然后调用 .Elem() 来获取“可设置” (settable) 的 Value。
3. 通过反射调用函数
- 使用
reflect.ValueOf()获取函数的Value。 - 准备一个
[]reflect.Value切片,作为函数的参数。 - 调用函数
Value的.Call()方法,传入参数切片。 .Call()会返回一个[]reflect.Value切片,即函数的返回值。
示例代码:
func hello(name string, age int) string {
return fmt.Sprintf("你好, %s! 你 %d 岁了。", name, age)
}
func main() {
// 1. 获取函数的 Value
funcValue := reflect.ValueOf(hello)
// 2. 准备参数
args := []reflect.Value{
reflect.ValueOf("张三"), // 第一个参数
reflect.ValueOf(20), // 第二个参数
}
// 3. 调用函数
returnValues := funcValue.Call(args)
// 4. 处理返回值
result := returnValues[0].String()
fmt.Println(result)
}
// 输出:
// 你好, 张三! 你 20 岁了。- golang的锁机制了解过吗? Mutex的锁有哪几种模式,分别介绍一下? Mutex锁底层如何实现了解过吗?
答案
1. Go 的锁机制
Go 的锁机制主要由 sync 包提供,核心是 sync.Mutex (互斥锁) 和 sync.RWMutex (读写锁)。
sync.Mutex:提供Lock()和Unlock()。一次只允许一个 Goroutine 进入临界区。sync.RWMutex:提供RLock()/RUnlock()(读锁) 和Lock()/Unlock()(写锁)。它允许多个“读者”同时访问,但“写者”必须独占访问。读写互斥,写写互斥。
2. Mutex 的锁模式
sync.Mutex 有两种模式,这是它的核心实现:
正常模式 (Normal Mode) (默认)
- 这是一个非公平锁 (Non-fair lock)。
- 当一个 Goroutine 释放锁时,所有等待的 Goroutine 会被唤醒并竞争锁。
- 优点: 性能极高。如果一个刚到来的 Goroutine (未等待) 尝试
Lock(),而此时锁正好被释放,它可以“闯入”并立即获取锁,而不需要唤醒那些已休眠的 Goroutine,这减少了上下文切换的开销。 - 缺点: 可能会导致“饥饿”(Starvation)。如果竞争激烈,某个等待队列中的 Goroutine 可能一直抢不到锁。
饥饿模式 (Starvation Mode)
- 这是一个公平锁 (Fair lock)。
- 触发条件: 当一个 Goroutine 尝试获取锁并失败,它会进入等待。如果它发现自己等待的时间超过了 1 毫秒,
Mutex就会切换到饥饿模式。 - 行为: 在饥饿模式下,锁的所有权不再竞争。当锁被释放时,它会直接传递给等待队列中的第一个 Goroutine(FIFO)。新来的 Goroutine 无法“闯入”,它们必须在队列末尾排队。
- 退出条件: 当一个 Goroutine 获取锁时,如果它是队列中的最后一个等待者,或者它获取锁的等待时间少于 1 毫秒,
Mutex就会切换回正常模式。
3. Mutex 底层实现
Mutex 底层通过两个核心字段实现:
state (int32):一个 32 位的整型,作为位掩码 (bitmask) 来存储锁的多种状态。mutexLocked(第 1 位): 标记锁是否已被持有。mutexWoken(第 2 位): 标记是否有 Goroutine 已被唤醒。mutexStarving(第 3 位): 标记是否处于饥饿模式。waiter count(剩余的 29 位): 记录有多少 Goroutine 在等待锁。
sema (uint32):一个底层的信号量,用于在 Goroutine 抢锁失败时,将其挂起(睡眠);并在锁释放时,将其唤醒。
Lock() 的简化流程:
- 快速路径 (Fast Path): 尝试通过原子操作 (CAS - Compare-And-Swap) 将
state的locked位从 0 置为 1。 - 如果 CAS 成功,goroutine 立即获得锁,函数返回。
- 慢速路径 (Slow Path): 如果 CAS 失败(锁已被持有):
- goroutine 会进入一个自旋(spinning)循环,尝试几次 CAS (仅限多核 CPU)。
- 自旋几次后仍失败,它会原子地增加
waiter count,并调用runtime_SemacquireMutex(信号量) 使自己进入睡眠。 - 在睡眠前,它会检查自己的等待时间,如果超过 1ms,则将
Mutex置为饥饿模式。
Unlock() 的简化流程:
- 快速路径: 通过原子操作将
state的locked位减 1 (解锁)。 - 如果解锁后的
state值为 0 (即没有等待者,也不是饥饿模式),则函数立即返回。 - 慢速路径: 如果
state不为 0 (有等待者或处于饥饿模式):- 它会调用
runtime_Semrelease(信号量),唤醒一个(或在饥饿模式下,精确地唤醒队列中的第一个)等待的 Goroutine。
- 它会调用
- channel、channel使用中需要注意的地方?
答案
channel 是 Go 中实现 CSP (Communicating Sequential Processes) 并发模型的核心工具,用于 Goroutine 之间的通信。
使用中需要注意的地方:
死锁 (Deadlock) - 阻塞
- 向
nilchannel 发送数据:永久阻塞。 - 从
nilchannel 接收数据:永久阻塞。 - 向无缓冲 channel 发送数据:如果没有“同时准备好”的接收者,会阻塞。
- 从无缓冲 channel 接收数据:如果没有“同时准备好”的发送者,会阻塞。
- 向已满的带缓冲 channel 发送数据:阻塞。
- 从已空的带缓冲 channel 接收数据:阻塞。
- 所有 Goroutine 都处于阻塞状态,会导致
fatal error: all goroutines are asleep - deadlock!
- 向
Panic - 崩溃
- 向已关闭 (closed) 的 channel 发送数据:会引发
panic: send on closed channel。 - 关闭一个已关闭 (closed) 的 channel:会引发
panic: close of closed channel。
- 向已关闭 (closed) 的 channel 发送数据:会引发
安全的操作 - 接收与关闭
- 从已关闭 (closed) 的 channel 接收数据:永远不会阻塞。它会立即返回该 channel 类型的零值(如
int的 0,string的 "")。 - 如何判断 channel 已关闭? 必须使用 "comma ok" 语法:go
val, ok := <-ch if !ok { // channel 已经关闭且已读完 fmt.Println("Channel closed!") } - 关闭规则:
- 永远不要让“接收方”去
close()channel,这极易引发恐慌。 - 安全原则: 应该由“发送方”在确定不会再发送数据时关闭 channel。
- 如果有多个发送方,应该使用
sync.WaitGroup来协调,在所有发送方都完成后,由一个中介 Goroutine 来关闭 channel。
- 永远不要让“接收方”去
- 从已关闭 (closed) 的 channel 接收数据:永远不会阻塞。它会立即返回该 channel 类型的零值(如
无缓冲 vs 带缓冲
- 无缓冲 (
make(chan int)):是同步的。发送和接收必须同时发生,用于确保两个 Goroutine 之间的同步点。 - 带缓冲 (
make(chan int, 10)):是异步的。在缓冲区满之前,发送方不会阻塞。它更像一个解耦的队列。不要误用它来“解决”死锁,应该用它来平滑峰值或解耦生产者/消费者。
- 无缓冲 (
select和default- 使用
select可以同时监听多个 channel。 select配合default子句可以实现非阻塞的发送和接收,避免死锁。
go// 非阻塞发送 select { case ch <- "data": // 发送成功 default: // ch 已满或无接收者,立即执行这里 }- 使用
- 数据库用的什么?数据库锁有了解吗?mysql锁机制讲一下。mysql分库分表。
答案
这个问题中的“数据库用的什么?”是问你(面试者)在项目中用了什么,你应该回答你熟悉的(如 MySQL, PostgreSQL)。我将回答后面的技术问题。
1. 数据库锁
数据库锁是为解决并发控制(ACID中的"I" - 隔离性)而设计的。
按粒度分:
- 表锁 (Table Lock):开销小,加锁快;但并发度最低,会锁定整张表。(如 MyISAM 引擎)。
- 行锁 (Row Lock):开销大,加锁慢;但并发度最高,只锁定操作的行。(如 InnoDB 引擎)。
- 页锁 (Page Lock):(BDB 引擎等,MySQL 中较少见)。
按模式(兼容性)分:
- 共享锁 (Shared Lock / S锁 / 读锁):多个事务可以同时持有 S 锁并读取数据。S 锁与 X 锁互斥。
- 排他锁 (Exclusive Lock / X锁 / 写锁):事务持有 X 锁时,可以修改数据。X 锁与 S 锁、X 锁都互斥。
2. MySQL 锁机制 (重点讲 InnoDB)
InnoDB 引擎是现代 MySQL 的默认引擎,它支持行级锁和 MVCC (多版本并发控制)。
MVCC (Multi-Version Concurrency Control):
- 这是 InnoDB 的基石。它使得“读-写”可以并发执行,读操作不加锁(快照读)。
- 它通过
Undo Log链保存数据的历史版本。在REPEATABLE READ(可重复读) 隔离级别下,事务启动时会创建一个“快照”(ReadView),后续所有SELECT都只读取该快照版本的数据,实现了可重复读和无锁读取。
InnoDB 的三种行锁算法:
- 记录锁 (Record Lock):最简单的行锁,它锁定单条索引记录。
- 间隙锁 (Gap Lock):它锁定一个索引范围,但不包括记录本身(即锁住“间隙”)。这是 InnoDB 在 RR 级别下解决幻读 (Phantom Reads) 的关键。例如,一个
WHERE id > 10的更新,会锁住 (10, +∞) 之间的所有间隙。 - 临键锁 (Next-Key Lock):这是 InnoDB 的默认行锁算法。它是记录锁 + 间隙锁的组合。它会锁定一个记录,以及该记录之前的那个间隙。
意向锁 (Intention Lock):
- 这是一种表级锁,但它不与行锁冲突,它只用于协调。
- 意向共享锁 (IS):事务打算在某几行上加 S 锁。
- 意向排他锁 (IX):事务打算在某几行上加 X 锁。
- 作用:如果一个事务想加“表级 X 锁”,它不需要去检查每一行是否有行锁,它只需要检查表上是否有 IS/IX 锁。如果有,说明其他事务正在操作行,它就必须等待。
3. MySQL 分库分表
当单表数据量过大(如超过 5000 万行)或 QPS 过高时,单一数据库会成为瓶颈,此时需要分库分表。
垂直拆分 (Vertical Sharding):
- 垂直分库:按业务拆分。例如
用户库、商品库、订单库。 - 垂直分表:将一个宽表(字段很多)拆分为多个窄表。例如
user_base(基础信息) 和user_profile(详情信息)。 - 优点:业务清晰,拆分简单。
- 缺点:无法解决“单一业务”的数据量瓶颈。
- 垂直分库:按业务拆分。例如
水平拆分 (Horizontal Sharding):
- 核心:将一个大表的数据,按照某个规则(Sharding Key)分散到多个结构相同的表(或库)中。
- Sharding Key (分片键):用于路由的字段(如
user_id,order_id)。 - 路由策略:
- 哈希取模 (Modulo):例如
user_id % 4。- 优点:数据分布均匀。
- 缺点:扩容极难。如果从 4 个表扩到 5 个表,几乎所有数据都要重算哈希并迁移。
- 范围 (Range):例如
user_id 1-1000万在表1,1001-2000万在表2。- 优点:扩容简单(加个新表即可)。
- 缺点:容易数据倾斜(“热点”数据)。
- 一致性哈希 (Consistent Hashing):(用于缓存较多,数据库较少)
- 优点:扩容时,只会影响环上相邻节点的数据,迁移量小。
- 哈希取模 (Modulo):例如
- 讲一下redis分布式锁?redis主从模式和集群模式的区别了解过吗?redis的数据类型有哪些?redis持久化怎么做的?
答案
1. Redis 分布式锁
实现 Redis 分布式锁的核心是利用 SET 命令的原子性。
加锁 (Atomic): 使用一个原子命令
SET key random_value NX PX milliseconds。key:锁的名称(如lock:order:123)。random_value:一个唯一的客户端标识(如 UUID)。用于安全解锁。NX:(Not Exists) 只在key不存在时才设置成功。这是实现“互斥”的关键。PX milliseconds:设置一个过期时间(如 30000 毫秒)。这是防止持有锁的客户端崩溃导致死锁。
解锁 (Atomic): 解锁必须是原子的,不能简单
DEL key。- 原因:如果 A 的锁超时(但 A 不知道),锁被 B 获取。此时 A 完成任务,
DEL了 B 的锁。 - 正确做法:使用 Lua 脚本。Lua 脚本在 Redis 中是原子执行的。
lua-- 检查 key 对应的 value 是否是我的 random_value if redis.call("get", KEYS[1]) == ARGV[1] then -- 是我的锁,我才能删除 return redis.call("del", KEYS[1]) else return 0 end在客户端,通过
EVAL命令执行此脚本,传入key和random_value。- 原因:如果 A 的锁超时(但 A 不知道),锁被 B 获取。此时 A 完成任务,
锁续期 (Watchdog): 如果业务执行时间可能超过锁的过期时间,需要一个“看门狗”后台线程,在锁即将过期时自动延长锁的时间。
2. 主从模式 vs 集群模式
| 特性 | 主从模式 (Master-Slave + Sentinel) | 集群模式 (Cluster) |
|---|---|---|
| 目标 | 高可用 (HA) + 读扩展 | 高可用 (HA) + 水平扩展 (Sharding) |
| 数据存储 | 数据冗余。每个节点(主/从)都拥有完整的数据集。 | 数据分片。数据被分散存储在多个 Master 节点上。 |
| 容量限制 | 整个数据集必须能装入单个 Master 的内存中。 | 理论上无限扩展,总容量是所有 Master 内存之和。 |
| HA 方案 | 依赖 Sentinel (哨兵) 系统来监控 Master,并在 Master 宕机时自动将 Slave 提升为新 Master。 | 内置 HA。每个 Master 都有自己的 Slaves。当 Master 宕机时,集群内部投票将其一个 Slave 提升为 Master。 |
| 写操作 | 只能写入 Master。 | 只能写入数据所在的那个“片”(Slot) 的 Master。 |
总结:
- 如果你的数据量不大(单机内存能放下),但需要高可用,用主从 + 哨兵。
- 如果你的数据量巨大(单机放不下),需要分片存储,用集群模式。
3. Redis 的数据类型 (5 种基础 + 3 种高级)
String(字符串):最基础的 K-V。用途:缓存、计数器 (INCR)。List(列表):有序的字符串列表(双向链表)。用途:队列 (LPUSH/RPOP)、时间线。Hash(哈希):K-V 映射(像 Go 的map[string]string)。用途:存储对象(如user:1->name "A", age "20")。Set(集合):无序、唯一的字符串集合。用途:标签、共同好友 (SINTER)。Sorted Set(ZSET / 有序集合):Set的升级版,每个成员都关联一个score(分数),按分数排序。用途:排行榜、范围查询。
- 高级:
Bitmaps(位图)、HyperLogLog(基数统计)、Streams(流)。
4. Redis 持久化
Redis 提供两种持久化方式,通常混合使用:
RDB (Redis Database)
- 原理:在特定时间点,将内存中的数据快照 (snapshot) 完整地写入磁盘上的一个二进制文件 (
.rdb)。 - 触发:手动
SAVE(阻塞) /BGSAVE(非阻塞),或自动(如save 60 1000:60秒内1000次写入)。 - 优点:文件紧凑,恢复速度快(直接加载文件)。
- 缺点:数据丢失多。如果 Redis 在两次快照之间崩溃,会丢失大量数据。
- 原理:在特定时间点,将内存中的数据快照 (snapshot) 完整地写入磁盘上的一个二进制文件 (
AOF (Append Only File)
- 原理:将每一条写命令(如
SET,INCR)追加 (append) 到一个文件 (.aof) 的末尾。 - 触发:
fsync策略(always: 每条命令,everysec: 每秒 (默认),no: 操作系统决定)。 - 优点:数据丢失少(默认最多 1 秒)。
- 缺点:文件比 RDB 大(因为是命令日志);恢复速度慢(需要重放所有命令)。
- 原理:将每一条写命令(如
现代 Redis (4.0+) 默认使用混合持久化: 在 AOF 重写时,Redis 会将当前的内存快照以 RDB 的格式写入 AOF 文件的开头,然后才追加增量命令。这结合了 RDB 恢复快和 AOF 数据丢失少的优点。
- 编程题:你了解的负载均衡算法有什么?实现一个负载均衡算法。
答案
了解的负载均衡算法
轮询 (Round Robin):按顺序循环选择服务器(1, 2, 3, 1, 2, 3...)。最简单,但假设所有服务器性能相同。
加权轮询 (Weighted Round Robin):根据服务器的权重分配请求。权重高的服务器被选中的几率更高。
IP 哈希 (IP Hash):根据客户端 IP 地址的哈希值来选择服务器。可以保证同一个客户端的请求总是落到同一台服务器上(用于
sticky session)。最少连接 (Least Connections):将新请求发送到当前活动连接数最少的服务器。适用于长连接和处理时间不均的请求。
随机 (Random):随机选择一台服务器。
最快响应时间 (Least Response Time):根据服务器最近的响应时间来分配,优先选择响应最快的。
实现一个负载均衡算法 (Go)
我们来实现一个线程安全的轮询 (Round Robin) 算法,这是最基础、最常见的。
关键点: 为了保证并发安全,我们不能使用普通的 int 计数器,而应该使用 atomic 包的原子操作,这比使用 sync.Mutex 更高效。
package main
import (
"fmt"
"sync/atomic"
)
// LoadBalancer 接口
type LoadBalancer interface {
GetNextServer() (string, error)
}
// RoundRobinLoadBalancer 轮询负载均衡器
type RoundRobinLoadBalancer struct {
servers []string // 服务器列表
next atomic.Uint64 // 使用原子计数器保证并发安全
}
// NewRoundRobinLoadBalancer 创建一个新的轮询均衡器
func NewRoundRobinLoadBalancer(servers []string) (LoadBalancer, error) {
if len(servers) == 0 {
return nil, fmt.Errorf("服务器列表不能为空")
}
return &RoundRobinLoadBalancer{
servers: servers,
}, nil
}
// GetNextServer 获取下一个服务器
func (lb *RoundRobinLoadBalancer) GetNextServer() (string, error) {
if len(lb.servers) == 0 {
return "", fmt.Errorf("没有可用的服务器")
}
// 1. 原子地增加计数器,并获取增加后的值
// 2. AddUint64 会处理溢出问题,自动回绕到 0,但为了可读性,我们通常还是取模
idx := lb.next.Add(1)
// 3. 计算索引
// 我们用 (idx-1) 来获取当前值,然后取模
// Add(1) 返回的是新值,所以我们减1得到当前轮的索引
// (idx-1) % len(servers)
// (更简洁的方式:直接用新值 % len,因为 1%3 和 4%3 和 7%3 结果都是 1)
// 使用 (idx - 1) 是为了让第一次调用从索引 0 开始
// Add(1) -> idx=1. (1-1)%3 = 0.
// Add(1) -> idx=2. (2-1)%3 = 1.
// Add(1) -> idx=3. (3-1)%3 = 2.
// Add(1) -> idx=4. (4-1)%3 = 0.
index := (idx - 1) % uint64(len(lb.servers))
return lb.servers[index], nil
}
// --- 模拟测试 ---
func main() {
servers := []string{
"http://server-1:80",
"http://server-2:80",
"http://server-3:80",
}
lb, err := NewRoundRobinLoadBalancer(servers)
if err != nil {
panic(err)
}
// 模拟 10 次请求
fmt.Println("模拟 10 次轮询请求:")
for i := 0; i < 10; i++ {
server, _ := lb.GetNextServer()
fmt.Printf("请求 %d -> %s\n", i+1, server)
}
}
// 输出:
// 模拟 10 次轮询请求:
// 请求 1 -> http://server-1:80
// 请求 2 -> http://server-2:80
// 请求 3 -> http://server-3:80
// 请求 4 -> http://server-1:80
// 请求 5 -> http://server-2:80
// 请求 6 -> http://server-3:80
// 请求 7 -> http://server-1:80
// 请求 8 -> http://server-2:80
// 请求 9 -> http://server-3:80
// 请求 10 -> http://server-1:80go get
核心功能是管理项目所需的外部代码库。-u是update的意思,自动更新包到最高版本。不加-u,则如果go.mod中有这个包的依赖,无论版本是什么,都不会更新。
go.sum和go.mod
go.mod用来记录直接依赖及其版本。
go.sum是一个自动生成的、包含依赖项检验和的锁定文件,以确保构建的可复现性和安全性。
八股文
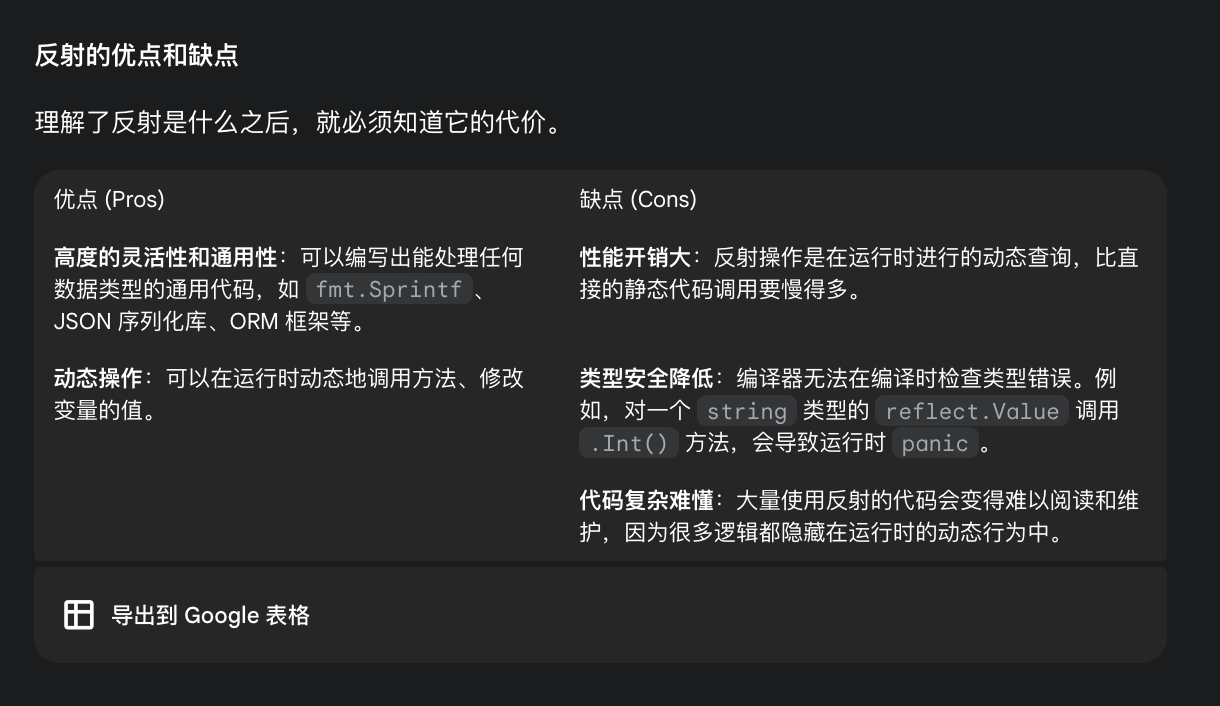
反射
进程
资源分配和CPU调度的基本单位。
线程
CPU调度的基本单位,线程除了有一些自己的必要的堆栈空间之外,其它的资源都是共享的线程中的,共享的资源包括:
- 所有线程共享相同的虚拟地址空间,即它们可以访问同样的代码段、数据段和堆栈段。
- 文件描述符:进程打开的文件描述符是进程级别的资源,所以同一个进程中的线程可以共享打开的文件描述符,这意味着它们可以同时读写同一个文件。
- 全局变量:全局变量是进程级别的变量,因此可以被同一个进程中的所有线程访问和修改。
- 静态变量:静态变量也是进程级别的变量,在同一个进程中的线程之间共享内存空间。
- 进程ID、进程组ID

优点:
- 创建一个新线程的代价要比创建一个新进程小的多
- 线程之间的切换相较于进程之间的切换需要操作系统做的工作很少
- 线程占用的资源要比进程少很多
- 能充分利用多处理器的可并行数量
- 等待慢速 IO操作结束以后,程序可以执行其他的计算任务
缺点:
- 性能损失( 一个计算密集型线程是很少被外部事件阻塞的,无法和其他线程共享同一个处理器,当计算密集型的线程的数量比可用的处理器多,那么就有可能有很大的性能损失,这里的性能损失是指增加了额外的同步和调度开销,二可用资源不变。)
- 健壮性降低(线程之间是缺乏保护性的。在一个多线程程序里,因为时间上分配的细微差距或者是共享了一些不应该共享的变量而造成不良影响的可能影响是很大的。)
- 缺乏访问控制( 因为进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。)
- 编程难度提高(编写和调试一个多线程程序比单线程困难的多。)
线程和进程切换
这你都能忘吗
进程是资源分配的基本单位,切换的时候:
- 保存现场:保存当前进程的所有CPU寄存器状态和内存管理信息(例如页表)
- 切换上下文:将CPU的控制权还给操作系统,然后更新内存管理单元(MMU),这个过程可能还要重新查询页表,最后更新各种数据结构并将进程状态从running改为ready
- 加载新现场:要加载新进程的内存管理信息、CPU寄存器状态并开始执行新进程
线程切换简单多了:
- 保存现场:只需要当前线程的私有数据,主要是cpu寄存状态和线程自己的栈
- 切换上下文:轻量,因为在一个地址空间内
- 加载新现场:加载新CPU寄存器状态和栈
相较之下,线程切换:
- 无需切换虚拟地址空间。
- 无需更改内存管理信息(页表)。
- 无需刷新TLB(快表)。当进程切换后,由于TLB是空的,所以最开始的访问都得访问多次内存,所以慢。
协程
用户态的线程,可以通过用户程序创建、删除。协程切换时不需要切换内核态。
协程与线程的区别:
- 线程是操作系统的概念,而协程是程序级的概念。线程由操作系统调度执行,每个线程都有自己的执行上下文,包括程序计数器、寄存器等。而协程由程序自身控制。
- 多个线程之间通过切换执行的方式实现并发。线程切换时需要保存和恢复上下文,涉及到上下文切换的开销。而协程切换时不需要操作系统的介入,只需要保存和恢复自身的上下文,切换开销较小。
- 线程是抢占式的并发,即操作系统可以随时剥夺一个线程的执行权。而协程是合作式的并发,协程的执行权由程序自身决定,只有当协程主动让出执行权时,其他协程才会得到执行机会。
有栈协程和无栈协程
- 有栈协程:把局部变量放入到新开的空间上,golang的实现,类似于内核态线程的实现,不同协程间切换还是要切换对应的栈上下文,只是不用陷入内核
- 无栈协程:直接把局部变量放入系统栈上,js、c++、rust那种await、async实现,主要原理就是闭包+异步,换句话说,其实就是协程的上下文都放到公共内存中,协程切换时,使用状态机来切换,就不用切换对应的上下文了,因为都在堆里的。比有栈协程都要轻量许多。
垃圾回收
去看上面的八股文内容。包括具体内容,触发条件和调优。
CSP模型
CSP模型是“以通信的方式来共享内存”,不同于传统的多线程通过共享内存来通信。用于描述两个独立的并发实体通过共享的通讯channel来进行通信的并发模型。
GMP
- G:goroutine,go的协程,每个go关键字都会创建一个协程
- M:machine,工作线程,在Go中称为Machine,数量对应真实的CPU数
- P:process,包含运行Go代码所需要的必要资源,用来调度G和M之间的关联关系,其数量可以通过GOMAXPROCS来设置,默认为核心数
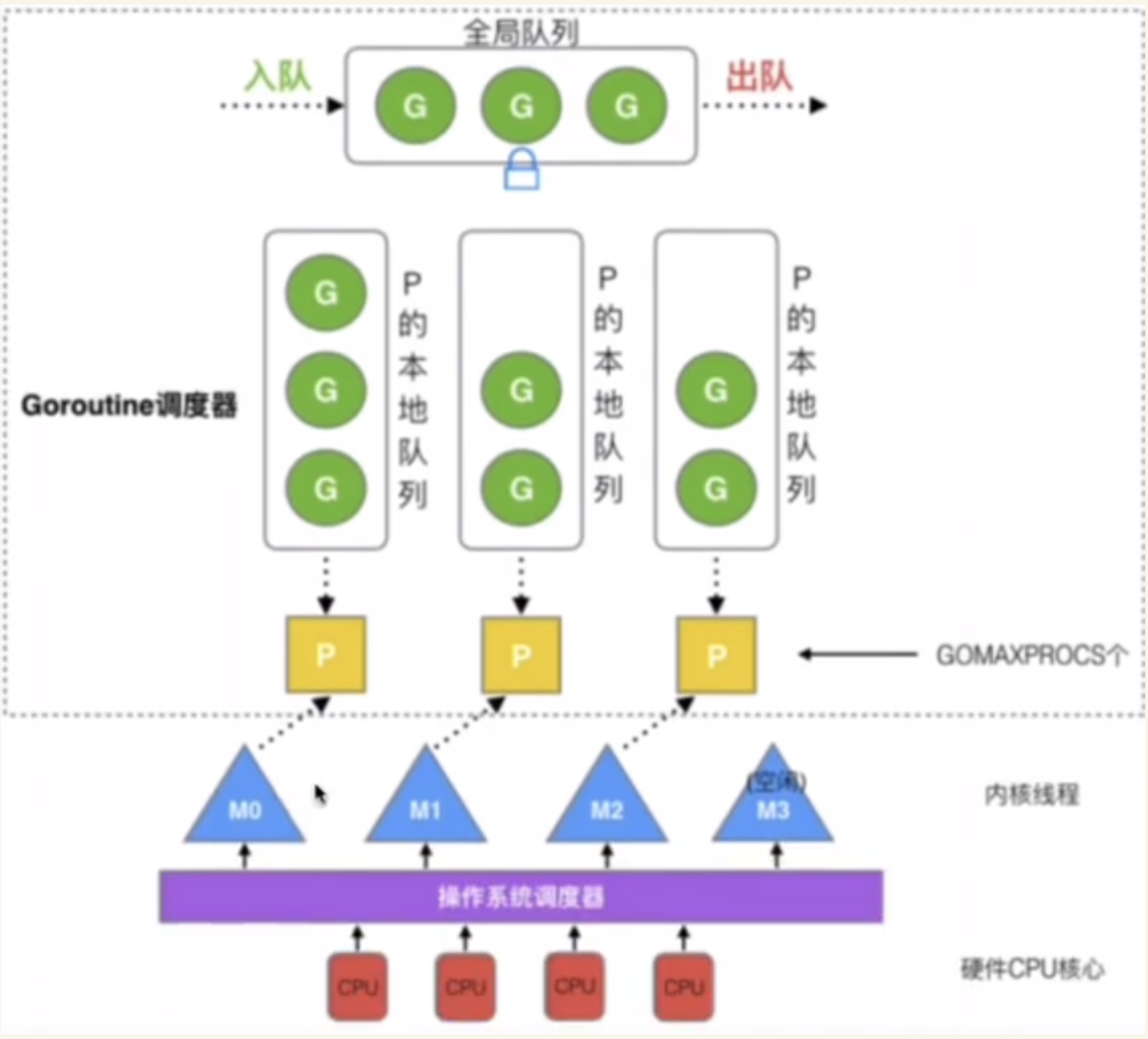
线程想运行任务就得获取 P,从 P 的本地队列获取 G,当 P 的本地队列为空时,M 也会尝试从全局队列或其他 P 的本地队列获取 G。M 运行 G,G 执行之后,M 会从 P 获取下一个 G,不断重复下去。
Goroutine调度策略
- 队列轮转:P会周期性的将G调度到M中执行,执行一段时间后,保存上下文,将G放到队列尾部,然后从队列中再取出一个G进行调度,P还会周期性的查看全局队列是否有G等待调度到M中执行
- 系统调用:当G0即将进入系统调用时,M0将释放P,进而某个空闲的M1获取P,继续执行P队列中剩下的G。M1的来源有可能是M的缓存池,也可能是新建的。
- 当G0系统调用结束后,如果有空闲的P,则获取一个P,继续执行G0。如果没有,则将G0放入全局队列,等待被其他的P调度。然后M0将进入缓存池睡眠。
Goroutine的切换时机
- select操作阻塞时
- io阻塞
- 阻塞在channel
- 程序员显示编码操作
- 等待锁
- 程序调用
Goroutine调度原理
调度循环:每个p都有一个协程g0,调度时首先切换到协程g0,切换到接下来将要运行的协程g,再从协程g切换到协程g0,开始新一轮调度。 从协程g0调度到协程g,经历了从schedule函数到execute函数再到gogo函数的过程。 schedule函数处理具体的调度策略,选择下一个要执行的协程。
execute函数执行一些具体的状态转移、协程g与结构体m之间的绑定等操作。 gogo函数是与操作系统有关的函数,用于完成栈的切换及CPU寄存器的恢复。
从协程g切换回协程g0时,mcall函数用于保存当前协程的执行现场。
Goroutine调度的本质就是将Goroutine(G)按照一定算法放到CPU上去执行。
CPU感知不到Goroutine,只知道内核线程,所以需要Go调度器将协程调度到内核线程上面去,然后操作系统调度器将内核线程放到CPU上去执行
M是对内核级线程的封装,所以Go调度器的工作就是将G分配到M
Go调度器的实现不是一蹴而就的,它的调度模型与算法也是几经演化,从最初的GM模型、到GMP模型,从不支持抢占,到支持协作式抢占,再到支持基于信号的异步抢占,经历了不断地优化与打磨。
被调度的对象:
- G的来源
P的runnext(只有1个G,局部性原理,永远会被最先调度执行) P的本地队列(数组,最多256个G) 全局G队列(链表,无限制) 网络轮询器network poller (存放网络调用被阻塞的G)
- P的来源
全局P队列(数组,GOMAXPROCS个P)
- M的来源
休眠线程队列(未绑定P,长时间休眠会等待GC回收销毁) 运行线程(绑定P,指向P中的G) 自旋线程((绑定P,指向M的GO)
运行线程数+自旋线程数<=P的数量(GOMAXPROCS),M个数>=P的个数
G的生命周期:
G从创建、保存、被获取、调度和执行、阻塞、销毁,步骤如下:
步骤1: 创建G,关键字go func()创建G
步骤2∶ 保存G,创建的G优先保存到本地队列P,如果P满了,则会平衡部分P到全局队列中。
保存G的详细流程如下: 执行go func的时候,主线程M0会调用newproc()生成一个G结构体,这里会先选定当前M0上的P结构 每个协程G都会被尝试先放到P中的runnext,若runnext 为空则放到runnext中,生产结束 若runnext满,则将原来runnext中的G踢到本地队列中,将当前G放到runnext中,生产结束 若本地队列也满了,则将本地队列中的G拿出一半,放到全局队列中,生产结束。
步骤3∶ 唤醒或者新建M执行任务,进入调度循环(步骤4,5,6)
步骤4∶ M获取G,M首先从P的本地队列获取G,如果P为空,则从全局队列获取G,如果全局队列也为 空,则从另一个本地队列偷取一半数量的G(负载均衡),这种从其它P愉的方式称之为work stealing
步骤5: M调度和执行G,M调用G.func()函数执行G
- 如果M在执行G的过程发生系统调用阻塞(同步),会阻塞G和M(操作系统限制),此时P会和当前M解绑, 并寻找新的M,如果没有空闲的M就会新建一个M,接管正在阻塞G所属的P,接着继续执行P中其余的 G,这种阻塞后释放P的方式称之为hand off。当系统调用结束后,这个G会尝试获取一个空闲的P执行, 优先获取之前绑定的P,并放入到这个P的本地队列,如果获取不到P,那么这个线程M变成休眠状态,加 入到空闲线程中,然后这个G会被放入到全局队列中。
- 如果M在执行G的过程发生网络IO等操作阻塞时(异步),阻塞G,不会阻塞M。M会寻找P中其它可执行的 G继续执行,G会被网络轮询器network poller接手,当阻塞的G恢复后,G1从network poller被移回到P的 LRQ中,重新进入可执行状态。异步情况下,通过调度,Go scheduler成功地将I/O的任务转变成了 CPU任务,或者说将内核级别的线程切换转变成了用户级别的goroutine切换,大大提高了效率。
步骤6∶ M执行完G后清理现场,重新进入调度循环(将M上运行的goroutine切换为G0,G0负责调度时 协程的切换)
调度策略:
抢占式调度
sysmon检测到协程运行过久(比如sleep,死循环) 切换到g0,进入调度循环
非协作式:就是由runtime来决定一个goroutine运行多长时间,如果你不主动让出,对不起,我有手段可以抢占你,把你踢出去,让后面的goroutine进来运行。
基于协作的抢占式调度流程:
- 编译器会在调用函数前插入runtime.morestack,让运行时有机会在这段代码中检查是否需要执行抢占 调度
- Go语言运行时会在垃圾回收暂停程序、系统监控发现Goroutine运行超过10ms,那么会在这个协程设置 一个抢占标记
- 当发生函数调用时,可能会执行编译器插入的runtime.morestack,它调用的runtime.newstack会检查抢 占标记,如果有抢占标记就会触发抢占让出cpu,切到调度主协程里
基于信号的抢占式调度 真正的抢占式调度是基于信号完成的,所以也称为“异步抢占"。不管协程有没有意愿主动让出cpu运行权,只要某个协程执行时间过长,就会发送信号强行夺取cpu运行权。
M注册一个SIGURG信号的处理函数:sighandler sysmon启动后会间隔性的进行监控,最长间隔10ms,最短间隔20us。如果发现某协程独占 P超过10ms,会给M发送抢占信号 M收到信号后,内核执行sighandler函数把当前协程的状态从_Grunning正在执行改成_Grunnable可执 行,把抢占的协程放到全局队列里,M继续寻找其他goroutine来运行 被抢占的G再次调度过来执行时,会继续原来的执行流
主动调度
新起一个协程和协程执行完毕触发调度循环 主动调用runtime.Gosched()切换到g0,进入调度循环。 垃圾回收之后。stw之后,会重新选择g开始执行
被动调度
- 系统调用(比如文件IO)阻塞(同步) 阻塞G和M,P与M分离,将P交给其它M绑定,其它M执行P的剩余G。
- 网络IO调用阻塞(异步) 阻塞G,G移动到NetPoller,M执行P的剩余G
- atomic/mutex/channel等阻塞(异步) 阻塞G,G移动到channel的等待队列中,M执行P的剩余G
使用什么策略来挑选下一个goroutine执行?
由于P中的G分布在runnext、本地队列、全局队列、网络轮询器中,则需要挨个判断是否有可执行的G,大体逻辑如下:
- 每执行61次调度循环,从全局队列获取G,若有则直接返回
- 从P上的runnext看一下是否有G,若有则直接返回
- 从P上的本地队列看一下是否有G,若有则直接返回
- 上面都没查找到时,则去全局队列、网络轮询器查找或者从其他Р中窃取,t一直阻塞直到获取到一个可用的G为止
netpoller中拿到的G是_Gwaiting状态(存放的是因为网络IO被阻塞的G),从其它地方拿到的是_Grunnable状态
Context 结构原理
Context(上下文)是Golang应用开发常用的并发控制技术 ,它可以控制一组呈树状结构的goroutine,每个goroutine拥有相同的上下文。Context 是并发安全的,主要是用于控制多个协程之间的协作、取消操作。
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}- 「Deadline」 方法:可以获取设置的截止时间,返回值 deadline 是截止时间,到了这个时间,Context 会自动发起取消请求,返回值 ok 表示是否设置了截止时间。
- 「Done」 方法:返回一个只读的 channel ,类型为 struct{}。如果这个 chan 可以读取,说明已经发出了取消信号,可以做清理操作,然后退出协程,释放资源。
- 「Err」 方法:返回Context 被取消的原因。
- 「Value」 方法:获取 Context 上绑定的值,是一个键值对,通过 key 来获取对应的值。
几个实现context接口的对象:
- context.Background()和context.TODO()相似,返回的context一般作为根对象存在,其不可以退出,也不能携带值。要具体地使用context的功能,需要派生出新的context。
- context.WithCancel()函数返回一个子context并且有cancel退出方法。子context在两种情况下会退出,一种情况是调用cancel,另一种情况是当参数中的父context退出时,该context及其关联的context都退出。
- context.WithTimeout函数指定超时时间,当超时发生后,子context将退出。因此子context的退出有3种时机,一种是父context退出;一种是超时退出;一种是主动调用cancel函数退出。
- context.WithDeadline()与context.WithTimeout()返回的函数类似,不过其参数指定的是最后到期的时间。
- context.WithValue()函数返回待key-value的子context
Context原理
context在很大程度上利用了通道在close时会通知所有监听它的协程这一特性来实现。每一个派生出的子协程都会创建一个新的退出通道,组织好context之间的关系即可实现继承链上退出的传递。
context使用场景:
- RPC调用
- PipeLine
- 超时请求
- HTTP服务器的request互相传递数据
Golang内存分配机制
Go语言内置运行时(就是runtime),抛弃了传统的内存分配方式,改为自主管理。这样可以自主地实现更好的内存使用模式,比如内存池、预分配等等。这样,不会每次内存分配都需要进行系统调用。
设计思想:
- 内存分配算法采用Google的 TCMalloc算法,每个线程都会自行维护一个独立的内存池,进行内存分配时
- 优先从该内存池中分配,当内存池不足时才会向加锁向全局内存池申请,减少系统调用并且避免不同线程
- 对全局内存池的锁竞争
- 把内存切分的非常的细小,分为多级管理,以降低锁的粒度
- 回收对象内存时,并没有将其真正释放掉,只是放回预先分配的大块内存中,以便复用。只有内存闲置过
- 多的时候,才会尝试归还部分内存给操作系统,降低整体开销
竞态/内存逃逸/内存对齐机制
去看八股文!!!整理不错的八股文
new和make的区别
var声明值类型的变量时,系统会默认为他分配内存空间,并赋该类型的零值 如果是指针类型或者引用类型的变量,系统不会为它分配内存,默认是nil。
- make 仅用来分配及初始化类型为 slice、map、chan 的数据。
- new 可分配任意类型的数据,根据传入的类型申请一块内存,返回指向这块内存的指针,即类型 *Type。
- make 返回引用,即 Type,new 分配的空间被清零, make 分配空间后,会进行初始。
- make函数返回的是slice、map、chan类型本身
- new函数返回一个指向该类型内存地址的指针
slice的实现原理
slice不是线程安全的,切片是基于数组实现的,底层是数组,可以理解为对底层数组的抽象。
type slice struct{
array unsafe.Pointer
len int
cap int
}- slice:占24个字节
- array:指向底层数组的指针,占用8个字节
- len:切片的长度,占用8个字节
- cap:切片的容量,cap总是大于等于len,占用8个字节
初始化slice调用的是runtime.makeslice,makeslice函数的工作主要就是计算slice所需内存大小,然后调用mallocgc进行内存的分配
所需内存的大小=切片中元素大小*切片的容量
array和slice的区别
- 数组长度不同
数组初始化必须指定长度,并且长度就是固定的
切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大
- 函数传参不同
数组是值类型,将一个数组赋值给另一个数组时,传递的是一份深拷贝,函数传参操作都会复制整个数组数据,会占用额外的内存,函数内对数组元素值的修改,不会修改原数组内容。
切片是引用类型,将一个切片赋值给另一个切片时,传递的是一份浅拷贝,函数传参操作不会拷贝整个切片,只会复制len和cap,底层共用同一个数组,不会占用额外的内存,函数内对数组元素值的修改,会修改原数组内容。
- 计算数组长度方式不同
数组需要遍历计算数组长度,时间复杂度为O(n)。切片底层包含len字段,可以通过len()计算切片长度,时间复杂度为O(1)
map实现方式 / 查找 / 扩容
Go中的map是一个指针,占用8个字节,指向hmap结构体,map底层是基于哈希表+链地址法存储的。
map的特点:
- 键不能重复
- 键必须可哈希(目前我们已学的数据类型中,可哈希的有:int/bool/float/string/array)
- 无序
去看八股文!!!整理不错的八股文
sync.Map
去看八股文!!!整理不错的八股文
Golang的map为什么是无序的?
使用range多次遍历map时输出的key和vabue 的顺序可能不同。这是Go语言的设计者们有意为之,旨在提示开发者们,Go底层实现并不保证map遍历顺序稳定,请大家不要依赖range遍历结果顺序
主要原因有2点:
- map在遍历时,并不是从固定的0号bucket开始遍历的,每次遍历,都会从一个随机值序号的bucket,再从其中随机的cell开始遍历
- map遍历时,是按序遍历bucket,同时按需遍历bucket中和其overflow bucket中的cell。但是map在扩容后,会发生key的搬迁,这造成原来落在一个buket中的Key,搬迁后,有可能会落到其他bucket中了,从这个角度看,遍历map的结果就不可能是按照原来的顺序了。map本身是无序的,且遍历时顺序还会被随机化,如果想顺序遍历map,需要对 map key先排序,再按照key 的顺序遍历map。
Channel的实现原理
Go中的channel是一个队列,遵循先进先出的原则,负责协程之间的通信(Go语言提倡不要通过共享内存 来通信,而要通过通信来实现内存共享,CSP(CommunicatingSequential Process)并发模型,就是通过 goroutine和channel来实现的)
使用场景:
- 停止信号监听
- 定时任务
- 生产方和消费方解耦
- 控制并发数
底层数据结构: 通过var声明或者make函数创建的channel变量是一个存储在函数栈帧上的指针,占用8个字节,指向堆上的hchan结构体,源码包中src/ runtime/ chan.go定义了hchan的数据结构: 
hchan结构体:
type hchan struct {
closed uint32 // channel是否关闭的标志
elemtype *_typel// channel中的元素类型
// channel分为无缓冲和有缓冲两种。
//对于有缓冲的channel存储数据,使用了ring buffer(环形缓冲区)来缓存写入的数据,本质是循环数组
//为啥是循环数组?普通数组不行吗,普通数组容量圄定更适合指定的空间,弹出元素时,普通数组需要全部都前移
//当下标超过数组容量后会回到第一个位置,所以需要有两个字段记录当前读和写的下标位置
buf unsafe.Pointer //指向底层循环数组的指针(环形缓冲区)
qcount uint //循环数组中的元素数量
dataqsiz uint //循环数组的长度
elemsize uint16 //元素的大小
sendx uint //下一次写下标的位置
recvx uint //下一次读下标的位置
//尝试读取channel或向channel写入数据面被阻塞的goroutine
recvq waitq //读等待队列
sendq waitq //写等特队列
lock mutex //互斥锁
}等待队列: 双向链表,包含一个头节点和一个尾节点 每个节点是一个sudog结构体变量,记录哪个协程在等待,等待的是哪个channel,等待发送/接收的数据在哪里
type waitq struct{
first *sudog
last *sudog
}
type sudog struct{
g *g //哪个协程在等待
next *sudog
prev *sudog
elem unsafe.Pointer //等待发送/接收的数据在哪里
c *hchan //等待的是哪个channel
...
}操作:
1. 创建
使用make(chan T, cap)来创建channel,make语法会在编译时,转换为makechan64和makechan
func makechan64(t *chantype, size int64) *hchan {
if int64(int(size)) != size {
panic(plainError("makechan: size out of range" ))
}
return makechan(t,int(size))
}make创建channel时会做一些检查:
- 元素大小不能超过64k
- 元素的对齐大小不能超过maxAlign也就是8字节
- 计算出来的内存是否超过限制
创建时的策略:
- 如果是无缓冲的channel,会直接给hchan分配内存
- 如果是有缓冲的channel,并且元素不包含指针,那么会为hchan和底层数组分配一段连续的地址
- 如果是有缓冲的channel,并且元素包含指针,那么会为hchan和底层数组分别分配地址
2. 发送:
发送操作,编译时转换为runtime.chansend函数
func chansend(c *hchan,ep unsafe.Pointer,block bool,callerpc uintptr) bool阻塞式: 调用chansend函数,并且block=true ch<-10
非阻塞式: 调用chansend函数,并且block=false select{ case ch <- 10: ... default } 向channel中发送数据时大概分为两大块:检查和数据发送,数据发送流程如下:
- 如果channel的读等待队列存在接收者goroutine将数据直接发送给第一个等待的goroutine,唤醒接收的goroutine
- 如果channel的读等待队列不存在接收者goroutine 如果循环数组buf未满,那么将会把数据发送到循环数组buf的队尾 如果循环数组buf已满,这个时候就会走阻塞发送的流程,将当前goroutine加入写等待队列,并挂起等 待唤醒
3. 接收:
发送操作,编译时转换为runtime.chanrecv函数 func chanrecv(c *hchan,ep unsafe.Pointer,block bool)(selected, received bool) 也包含阻塞和非阻塞式
向channel中接收数据时大概分为两大块,检查和数据发送,而数据接收流程如下:
如果channel的写等待队列存在发送者goroutine 如果是无缓冲channel,直接从第一个发送者goroutine那里把数据拷贝给接收变量,唤醒发送的 goroutine 如果是有缓冲channel(已满),将循环数组buf的队首元素拷贝给接收变量,将第一个发送者goroutine的 数据拷贝到buf循环数组队尾,唤醒发送的goroutine
如果channel的写等待队列不存在发送者goroutine 如果循环数组buf非空,将循环数组buf的队首元素拷贝给接收变量 如果循环数组buf为空,这个时候就会走阻塞接收的流程,将当前goroutine 加入读等待队列,并挂起等 待唤醒
当通道的元素类型包含指针时,确实需要单独分配内存空间的原因主要有以下两个方面:
避免竞争条件:在多个Goroutine之间共享内存时,需要确保内存的安全和一致性。当通道的元素类型为指针时,不同的Goroutine可 能会同时修改或访问同一个指针指向的内存区域,造成竞争条件。为了避免这种情况,通道会对每个元素都单独分配内存空间,确保 每个Goroutine都持有独立的内存副本,避免竞争条件的发生。
管理生命周期:通道作为一种线程安全的数据传输机制,其内部会负责管理元素的生命周期。当通道的元素类型为指针时,通道会确 保在元素被发送或接收完成后,正确释放对应的内存空间。通过单独分配内存空间,通道可以更好地管理元素的生命周期,防止内存 泄漏等问题的发生。 channel是并发安全的:
通道的发送和接收操作是原子的,即一个完整的发送或接收操作是一个原子操作,不会被其他goroutine中断。
当一个goroutine向channel发送数据时,如果channel已满,则发送操作会被阻塞,直到有其他goroutine从该channel中接收数据后释放 空间,发送操作才能继续执行。在这种情况下,channel内部会获取一个锁,保证只有一个goroutine能够往其中写入数据。
同样地,当一个goroutine从channel中接收数据时,如果channel为空,则接收操作会被阻塞,直到有其他goroutine向该channel中发送 数据后才能继续执行。在这种情况下,channel内部也会获取一个锁,保证只有一个goroutine能够从其中读取数据。
Channel是同步的还是异步的?
Channel是异步(asynchronous)进行的, channel存在3种状态:
- nil,未初始化的状态,只进行了声明,或者手动赋值为nil
- active,正常的channel,可读或者可写
- closed,已关闭,千万不要误认为关闭channel后,channel的值是nil,对已关闭channel读写都会panic
Channel死锁场景
- 非缓存channel只写不读
- 非缓存channel读在写后面
- 缓存channel写入超过缓冲区数量
- 空读
- 多个协程相互等待
Golang互斥锁的实现原理 / Goroutine的枪锁模式
去看八股文!!!整理不错的八股文
读写锁原理
RWMutex的5个方法:
- Lock/Unlock——写操作时调用的方法
- RLock/RUnlock——读操作时调用的方法
- RLocker——读操作时返回的Locker接口的对象——它的Lock方法会调用RLock,Unlock方法会调用RUnlock方法
type RWMutex struct{
w Mutex //互斥锁
writerSem uint32 //信号量,写锁等待读取完成
readerSem uint32 //信号量,读锁等待写入完成
readerCount int32 //当前正在执行的读操作的数量
readerWait int32 //写操作被阻塞时等待的读操作数量
}读锁操作:
- 先通过原子操作将readerCount加1
- 如果readerCount>=0就直接返回,所以如果只有获取读取锁的操作,那么其成本只有一个原子操作
- 当readerCount<0时,说明当前有写锁,当前协程将借助信号量陷入等待状态,如果获取到信号量则直接退出,没有获取到信号量时的逻辑与互斥锁的逻辑相似
- 读锁解锁时,如果当前没有写锁,则其成本只有一个原子操作并直接退出
- 如果当前有写锁正在等待,则调用rUnlockSlow判断当前是否为最后一个被释放的读锁,如果是则需要增加信号量并唤醒写锁
写锁操作:
- 写锁申请时必须先获取互斥锁,因为它复用了互斥锁的功能。接着readerCount减去rwmutexMaxReaders阻止后续读操作
- 获取到互斥锁并不一定能直接获取写锁,如果当前已经有其它Goroutine持有互斥锁的读锁,那么当前协程会加入全局等待队列并进入休眠状态,当最后一个读锁被释放时,会唤醒该协程
- 解锁时,调用Unlock方法,将readerCount加上rwmutexMaxReader,表示不会阻塞后序的读锁,依次唤醒所有等待中的读锁,当所有的读锁唤醒完毕后会释放互斥锁
Golang的原子操作有哪些?
Go atomic包是最轻量级的锁(也称无锁结构),可以在不形成临界区和创建互斥量的情况下完成并发安全的值替换操作,不过这个包只支持int32/Int64/uint32/uint64/uintptr这几种数据类型的一些基础操作(增减、交换、载入、存储等)
概念∶
原子操作仅会由一个独立的CPU指令代表和完成。原子操作是无锁的,常常直接通过CPU指令直接实现。事实上,其它同步技术的实现常常依赖于原子操作。
使用场景:
当我们想要对某个变量并发安全的修改,除了使用官方提供的 mutex,还可以使用sync/atomic包的原子操作,它能够保证对变量的读取或修改期间不被其他的协程所影响。 atomic 包提供的原子操作能够确保任一时刻只有一个goroutine对变量进行操作,善用atomic能够避免程序中出现大量的锁操作。
常见操作:
- 增减Add
- 载入Load
- 比较并交换CompareAndSwap
- 交换Swap
- 存储Store
atomic操作的对象是一个地址,你需要把可寻址的变量的地址作为参数传递给方法,而不是把变量的值传递给方法
下面将分别介绍这些操作:
- 增减操作:
// 此类操作的前缀为Add
func AddInt32(addr *int32,delta int32)(new int32)
func AddInt64(addr *int64, delta int64) 《new int64)
func AddUint32(addr *uint32, delta uint32)(new uint32)
func AddUint64(addr suint64,delta uint64)(new uint64)
func AddUintptr(addr *uintptr,delta uintptr) (new uintptr)func add(addr *int64, delta int64) {
atomic.AddInt64(addr, delta)//加操作
fmt.Println("add opts: ",*addr)
}- 载入操作:
// 此类操作的前缀为Load
func LoadInt32( addr *int32)(val int32)
func LoadInt64(addr *int64)(val int64)
func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer)
func LoadUint32( addr *uint32)(val uint32)
func LoadUint64(addr *uint64) (val uint64)
func LoadUintptr(addr *uintptr) (val uintptr)
// 特殊类型:Value类型,常用于配置变更
func (v *Value) Load() (x interface{}){}- 比较并交换:
// 此类操作的前缀为CompareAndSwap,该操作简称CAS,可以用来实现乐观锁
func CompareAndSwapInt32(addr *int32,old,new int32)(swapped bool)
func CompareAndSwapInt64(addr *int64,old,new int64) (swapped bool)
func CompareAndSwapPointer(addr *unsafe.Pointer,old,new unsafe.Pointer) (swapped bool)
func CompareAndSwapUint32(addr *uint32,old,new uint32)(swapped bool)
func CompareAndSwapUint64(addr *uint64,old,new uint64) (swapped bool)
func CompareAndSwapUintptr(addr *uintptr,old,new uintptr) (swapped bool)该操作在进行交换前首先确保变量的值未被更改,即仍然保持参数old 所记录的值,满足此前提下才进行交换操作。CAS的做法类似操作数据库时常见的乐观锁机制。
需要注意的是,当有大量的goroutine对变量进行读写操作时,可能导致CAS操作无法成功,这时可以利用for循环多次尝试。
原子操作和锁的区别
- 原子操作由底层硬件支持,而锁是基于原子操作+信号量完成的。若实现相同的功能,前者通常会更有效率
- 原子操作是单个指令的互斥操作;互斥锁/读写锁是一种数据结构,可以完成临界区(多个指令)的互斥操作,扩大原子操作的范围
- 原子操作是无锁操作,属于乐观锁;说起锁的时候,一般属于悲观锁
- 原子操作存在于各个指令/语言层级,比如*机器指令层级的原子操作",““汇编指令层级的原子操作”,“Go语言层级的原子操作”等。
- 锁也存在于各个指令/语言层级中,比如“机器指令层级的锁”,“汇编指令层级的锁“Go语言层级的锁“等
Goroutine的实现原理
Goroutine可以理解为一种Go语言的协程(轻量级线程),是Go支持高并发的基础,属于用户态的线程,由Goruntime管理而不是操作系统。
Goroutine的泄露
原因:
- Goroutine内进行channel/mutex等读写操作被一直阻塞。
- Goroutine内的业务逻辑进入死循环,资源一直无法释放。
- Goroutine内的业务逻辑进入长时间等待,有不断新增的Goroutine进入等待
怎么查看Goroutine的数量?怎么限制Goroutine的数量?
在开发过程中,如果不对goroutine加以控制而进行滥用的话,可能会导致服务整体崩溃。比如耗尽系统资源导致程序崩溃,或者CPU使用率过高导致系统忙不过来。
- 在Golang中,GOMAXPROCS中控制的是未被阻塞的所有Goroutine,可以被 Multiplex 到多少个线程上运行,通过GOMAXPROCS可以查看Goroutine的数量。
- 使用通道。每次执行的go之前向通道写入值,直到通道满的时候就阻塞了
Goroutine和线程的区别?
- 一个线程可以有多个协程
- 线程、进程都是同步机制,而协程是异步
- 协程可以保留上一次调用时的状态,当过程重入时,相当于进入了上一次的调用状态
- 协程是需要线程来承载运行的,所以协程并不能取代线程,「线程是被分割的CPU资源,协程是组织好的代码流程」
Go的Struct能不能比较?
- 相同struct类型的可以比较
- 不同struct类型的不可以比较,编译都不过,类型不匹配
Go的Slice如何扩容?
go1.18之前:
- 首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)。
- 否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍。
- 否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的1.25倍,直到新最终容量大于等于新申请的容量
- 如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)。
go1.18之后: 低于256,每次扩容两倍。超过256,不再是每次扩容1/4,而是每次增加(旧容量+3*256)/4即1.25倍+192
在Go函数中为什么会发生内存泄露?发生了泄漏如何检测?
Goroutine 需要维护执行用户代码的上下文信息,在运行过程中需要消耗一定的内存来保存这类信息,如果一个程序持续不断地产生新的 goroutine,且不结束已经创建的 goroutine 并复用这部分内存,就会造成内存泄漏的现象。 可以通过Go自带的工具pprof或者使用Gops去检测诊断当前在系统上运行的Go进程的占用的资源。
Go中两个Nil可能不相等吗?
Go中两个Nil可能不相等。 接口(interface) 是对非接口值(例如指针,struct等)的封装,内部实现包含 2 个字段,类型 T 和 值 V。一个接口等于 nil,当且仅当 T 和 V 处于 unset 状态(T=nil,V is unset)。 两个接口值比较时,会先比较 T,再比较 V。接口值与非接口值比较时,会先将非接口值尝试转换为接口值,再比较
func main() {
var p *int = nil
var i interface{} = p
fmt.Println(i == p) // true
fmt.Println(p == nil) // true
fmt.Println(i == nil) // false
}Go语言中的内存对齐
CPU 并不会以一个一个字节去读取和写入内存。相反 CPU 读取内存是一块一块读取的,块的大小可以为 2、4、6、8、16 字节等大小。块大小我们称其为内存访问粒度,内存访问粒度跟机器字长有关。 对齐规则:
- 结构体的成员变量,第一个成员变量的偏移量为 0。往后的每个成员变量的对齐值必须为编译器默认对齐长度或当前成员变量类型的长度,取最小值作为当前类型的对齐值。其偏移量必须为对齐值的整数倍
- 结构体本身,对齐值必须为编译器默认对齐长度,或结构体的所有成员变量类型中的最大长度,取最大数的最小整数倍作为对齐值
- 结合以上两点,可得知若编译器默认对齐长度,超过结构体内成员变量的类型最大长度时,默认对齐长度是没有任何意义的
两个 interface 可以比较吗?
判断类型是否一样 reflect.TypeOf(a).Kind() == reflect.TypeOf(b).Kind()
判断两个interface{}是否相等 reflect.DeepEqual(a, b)
将一个interface{}赋值给另一个interface{} reflect.ValueOf(&a).Elem().Set(reflect.ValueOf(b))
go 打印时 %v %+v %#v 的区别?
- %v 只输出所有的值;
- %+v 先输出字段名字,再输出该字段的值;
- %#v 先输出结构体名字值,再输出结构体(字段名字+字段的值);
package main
import "fmt"
type student struct {
id int32
name string
}
func main() {
a := &student{id: 1, name: "微客鸟窝"}
fmt.Printf("a=%v \n", a) // a=&{1 微客鸟窝}
fmt.Printf("a=%+v \n", a) // a=&{id:1 name:微客鸟窝}
fmt.Printf("a=%#v \n", a) // a=&main.student{id:1, name:"微客鸟窝"}
}什么是 rune 类型?
Go语言的字符有以下两种:
- uint8 类型,或者叫 byte 型,代表了 ASCII 码的一个字符。
- rune 类型,代表一个 UTF-8 字符,当需要处理中文、日文或者其他复合字符时,则需要用到 rune 类型。rune 类型等价于 int32 类型。
空 struct{} 占用空间么?用途是什么?
空结构体 struct{} 实例不占据任何的内存空间。
用途:
- 将 map 作为集合(Set)使用时,可以将值类型定义为空结构体,仅作为占位符使用即可。
- 不发送数据的信道(channel)使用 channel 不需要发送任何的数据,只用来通知子协程(goroutine)执行任务,或只用来控制协程并发度。
- 结构体只包含方法,不包含任何的字段
golang值接收者和指针接收者的区别
golang函数与方法的区别是,方法有一个接收者。
- 如果方法的接收者是指针类型,无论调用者是对象还是对象指针,修改的都是对象本身,会影响调用者
- 如果方法的接收者是值类型,无论调用者是对象还是对象指针,修改的都是对象的副本,不影响调用者
通常我们使用指针类型作为方法的接收者的理由:
- 使用指针类型能够修改调用者的值
- 使用指针类型可以避免在每次调用方法时复制该值,在值的类型为大型结构体时,这样做更加高效
引用传递和值传递
什么是引用传递?
将实参的地址传递给形参,函数内对形参值内容的修改,将会影响实参的值内容。
Go语言是没有引用传递的,只有 pass by value,在C++中,函数参数的传递方式有引用传递。
Go的值类型(int、struct等)、引用类型(指针、slice、map、 channel)
- int类型:形参和实际参数内存地址不一样,证明是值传递﹔参数是值类型,所以函数内对形参的修改,不会修改原内容数据
- 指针类型:形参和实际参数内存地址不一样,证明是值传递,由于形参和实参是指针,指向同一个变量。函数内对指针指向变量的修改,会修改原内容数据
函数调用时,传递的依然是指针的副本,依然是值传递,但指针指向的是同一个地址,所以能修改值 slice:slice 是一个结构体,他的第一个元素是一个指针类型,这个指针指向的是底层数组的第一个元素。当参数是slice类型的时候,fmt.Printf通过%p打印的slice变量的地址其实就是内部存储数组元素的地址,所以打印出来形参和实参内存地址一样。
我自己的测试
对于切片来说,都是可以改原数组的,只要cap(arr)不变,都是在操控原数组,比如先缩小切片长度再扩大切片长度,只要不超过原切片的capacity,都还是操作原数组,但是一旦先扩容使得cap变了,那golang就会先开辟新的空间复制过去,那就和原数组没有关系了。
对于make可以创建的东西:slice, map, chan:这三种类型被称为描述符类型或头指针类型,它们本身是一个小的数据结构(一个“头”或“描述符”),其中包含一个指向底层真正数据结构的指针。在传递的时候,其实还是值传递,但是复制的是这个,描述符,即地址。
对于其他类型:int, bool, string, struct, array:变量实际上就是数据本身,而不是指针类型,这个时候就要用到指针。非常经典的东西:sync.WaitGroup
defer关键字的实现原理
Go14中编译器会将defer函数直接插入到函数的尾部,无需链表和栈上参数拷贝,性能大幅提升。把defer函数在当前函数内展开并直接调用,这种方式被称为open code defer
- 函数退出前,按照先进后出的顺序,执行defer函数
- panic后的defer不会被执行(遇到panic,如果没有捕获错误,函数会立刻终止)
- panic没有被recover时,抛出的panic到当前goroutine最上层函数时,最上层程序直接异常终止
- panic有被recover时,当前goroutine最上层函数正常执行
panic发生后,会自动依次往上层去执行defer函数,并且panic之后的函数不会被执行,即使是被recover
大概的流程就是,如果遇见panic关键字的话,那么go执行器就会进入代码gopanic函数中,进入之后会拿到表示当前协程g的指针,然后通过该指针拿到当前协程的defer链表,通过for循环来进行执行defer,如果在defer中又遇见了panic的话,则会释放这个defer,通过continue去执行下一个defer,然后就是一个一个的执行defer了,如果在defer中遇见recover,那么将会通过mcall(recovery)去执行panic.
Select底层原理
select的每一个case在运行时都是一个scase结构体,存放了通道和通道中的元素类型等信息。
type scase struct{
c *hchan
elem unsafe.Pointer
kind uint16
...
}scase结构体中的kind代表scase的类型。scase一共有4种具体的类型,分别为caseNil、caseRecv、caseSend及caseDefault。caseNil代表当前分支中的通道为nil,caseRecv代表当前分支从通道接收消息,caseSend代表当前分支发送消息到通道,caseDefault代表当前分支为default分支。pollorder通过引入随机数的方式给序列带来了随机性。
- select运行时会调用核心函数selectgo,selectgo有两个关键的序列,分别是pollorder和lockorder。
- pollorder代表乱序后的scase序列,pollorder通过引入随机数的方式给序列带来了随机性。
- lockorder是按照大小对通道地址排序,对所有的scase按照其通道在堆区的地址大小,使用大根堆排序算法进行排序。selectgo会按照该序列依次对select中所有的通道加锁。而按照地址排序的目的是避免多个协程并发加锁时带来的死锁问题。
当对所有的scase中的通道加锁完毕后,selectgo开始了一轮对于所有scase的循环。循环的目的是找到当前准备好的通道。
- 如果scase的类型为caseNil,则会被忽略。
- 如果scase的类型为caseRecv,则和普通的通道接收一样,先判断是否有正在等待写入当前通道的协程,如果有则直接跳转到对应的recv分支。接着判断缓冲区是否有元素,如果有则直接跳转到bufrecv分支执行。
- 如果scase的类型为caseSend,则和普通的通道发送一样,先判断是否有正在等待读取当前通道的协程,如果有,则跳转到send分支执行,接着判断缓冲区是否空余,如果有,则跳转到bufsend分支执行。
- 如果scase的类型为caseDefault,则会记录下来,并在循环完毕发现没有已经准备好的通道后,判断是否存在caseDefault类型,如果有,则跳转到retc分支执行。
- 当任何一个case都不满足时,当前协程进入休眠状态,不管是读取通道还是写入通道都需要创建一个新的sudog并放入指定通道的等待队列,之后当前协程将进入休眠状态。当select case中的任意一个通道不再阻塞时,当前协程将被唤醒。要注意的是,最后需要将sudog结构体在其他通道的等待队列中出栈,因为当前协程已经能够正常运行,不再需要被其他通道唤醒。
gRPC
gRPC是基于go的远程过程调用。RPC 框架的目标就是让远程服务调用更加简单、透明,RPC 框架负责屏蔽底层的传输方式(TCP 或者 UDP)、序列化方式(XML/Json/ 二进制)和通信细节。服务调用者可以像调用本地接口一样调用远程的服务提供者,而不需要关心底层通信细节和调用过程。
gRPC和RPC对比
gRPC是一种高性能,通用的远程过程调用(RPC)框架,采用基于HTTP/2的二进制传输协议实现可以实现双向流、头部压缩和多路复用等,使用Protocol Buffers作为默认的序列化协议。 GRPC和RPC区别:
- 通信协议不同:gRPC是基于HTTP/2协议进行数据传输,而传统的RPC框架通常使用TCP和UDP等传输层协议
- 序列化方式不同:gRPC使用Protocol Buffers作为默认的序列化协议,而传统的RPC框架使用JSON、XML等格式。
- 支持多种语言:gRPC支持多种编程语言,包括C++、Java、Python、Go、Ruby等,而传统的RPC框架通常只支持少数几种语言
- 高性能:由于采用了HTTP/2协议和Protocol Buffers序列化协议,gRPC具有更高的性能和效率
- 自动生成代码:gRPC可以根据服务定义文件自动生成客户端和服务端的代码,大大简化了开发过程。
- 安全性:gRPC提供了TLS加密和认证等安全机制,保障通信的安全性。
设计模式
设计模式分为三类:
- 创建型模式:用于控制对象的创建过程
- 结构型模式:用于处理类和对象之间的关系
- 行为型模式:用于描述对象之间的通信和协作
eg:
1.工厂模式(Factory Pattern)是一种创建型模式,它提供了一种统一的接口来创建对象,但是具体的对象创建过程则由子类来实现。工厂模式可以将对象的创建和使用解耦,使得代码更加灵活和可扩展。常见的工厂模式有简单工厂模式、工厂方法模式和抽象工厂模式。
2.代理模式(Proxy Pattern)是一种结构型模式,它为其他对象提供一种代理,以控制对这个对象的访问。代理模式可以在不改变原始对象的情况下,增加一些额外的功能或限制对原始对象的访问。常见的代理模式有静态代理和动态代理。
3.建造者模式(Builder Pattern)是一种创建型模式,它将一个复杂对象的创建过程分解成多个简单的步骤,从而可以灵活地组合这些步骤来构建不同的对象。建造者模式可以避免使用多个参数构造函数的情况,使得代码更加清晰和可读。同时,建造者模式还可以通过链式调用来简化对象的构建过程。
golang中指针的作用
- 传递大对象
- 修改函数外部变量
- 动态分配内存
- 函数返回指针
协程池
协程已经很轻量了,为什么还要有协程池?
- 限制协程的数量,不让协程无限制地增长
- 减少GC和协程创建的开销
Sync.Pool的使用
sync.Pool 本质用途是增加临时对象的重用率,减少 GC 负担。
sync.Pool 中保存的元素有如下特征:
- Pool 池里的元素随时可能释放掉,释放策略完全由 runtime 内部管理;
- Get 获取到的元素对象可能是刚创建的,也可能是之前创建好 cache 的,使用者无法区分;
- Pool 池里面的元素个数你无法知道;
JWT
jwt结构: 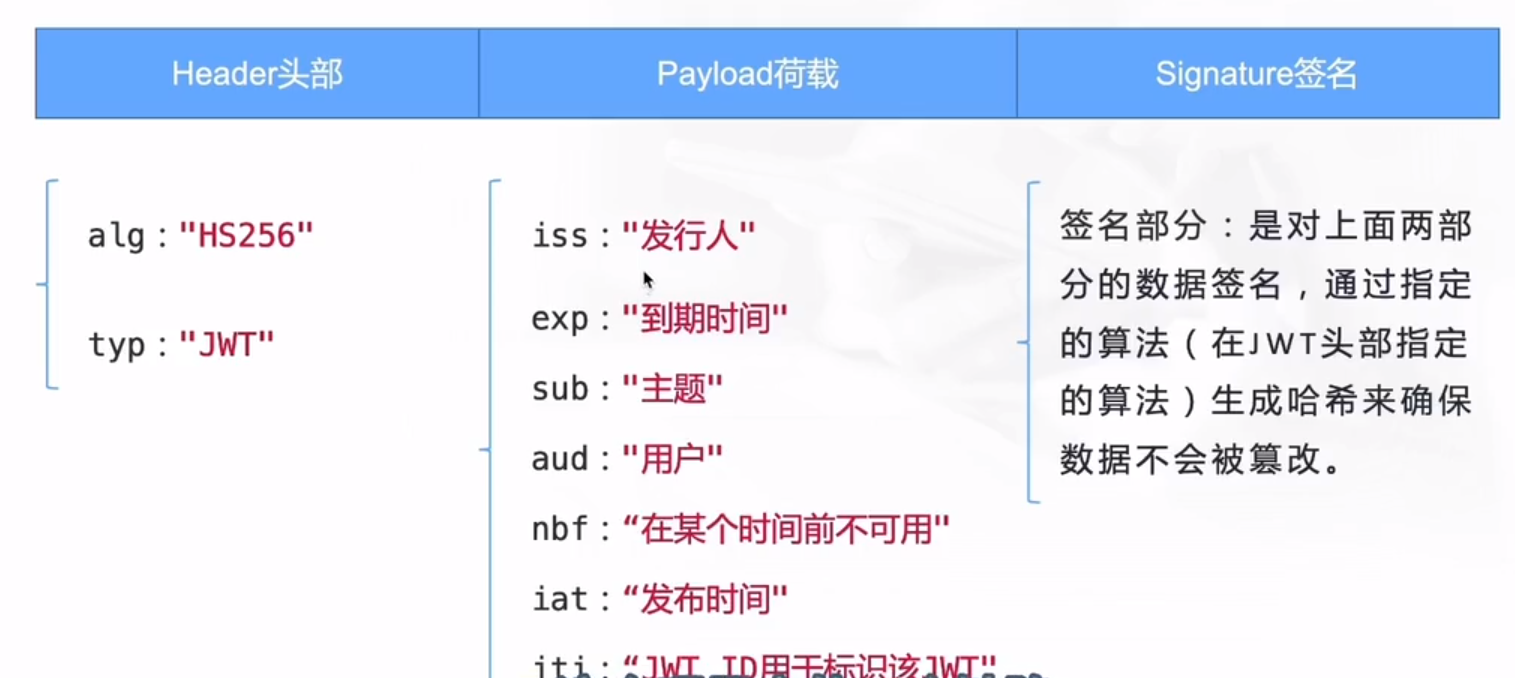 jwt认证授权过程:
jwt认证授权过程:
- 客户端发送账号密码等一些登陆信息给服务端
- 服务端验证通过之后,通过上述jwt的字段信息,返回给客户端一个token
- 之后的客户端每次请求都把这个token放到头部
- 服务端需要授权的接口会先拿到token进行解析来检验token并且获取用户的信息
HTTP和RPC对比
- RPC(Remote Produce Call):远程过程调用,
- HTTP:网络传输协议
相同点:
- 都是基于TCP协议的应用层协议
- 都可以实现远程调用,服务调用服务
不同点:
- RPC主要用于在不同的进程或计算机之间进行函数调用和数据交换。HTTP主要用于数据传输和通信。
- RPC协议通常采用二进制协议和高效的序列化方式,而HTTP通常采用文本协议和基于ASCII码的编码方式,数据传输效率较低
- RPC通常需要使用专门的IDL文件来定义服务和消息类型,生成服务端和客户端的代码。而HTTP没有这个限制,可以使用套接字进行通信
String和[]byte的区别
string类型本质也是一个结构体,定义如下:
type stringStruct struct {
str unsafe.Pointer
len int
}string类型底层是一个byte类型的数组,stringStruct和slice还是很相似的,str指针指向的是byte数组的首地址,len代表的就是数组长度。
string和byte的区别:
string类型为什么还要在数组的基础上再进行一次封装呢?
这是因为在Go语言中string类型被设计为不可变的,不仅是在Go语言,其他语言中string类型也是被设计为不可变的,这样的好处就是:在并发场景下,我们可以在不加锁的控制下,多次使用同一字符串,在保证高效共享的情况下而不用担心安全问题。
常见字符集
- ASCII:采用了一个字节存储一个字符,首位是0,总共能能表示128个字符(英文、符号等)
- UTF-8:是Unicode字符集的一种编码方案,采取可变长编码方案,总共分为四个长度区:1个字节、2个字节、3个字节、4个字节。英文字符、数字等只占1个字节(兼容标准ASCII编码),汉字字符占用3个字节。
- UTF-16:编码时以2个字节为基本单位
- UTF-32:4个字节表示一个字符,定长编码
Golang字符串拼接对比
- +号拼接:因为golang的字符串是静态的,所以每次+都会重新分配一个内存空间存相加的两个字符串
- fmt.Sprintf:主要是使用到了反射
- Strings.Builder:
type Builder struct {
addr *Builder // of receiver, to detect copies by value
buf []byte // 1
}- addr字段主要是做copycheck,buf字段是一个byte类型的切片,这个就是用来存放字符串内容的,提供的writeString()方法就是像切片buf中追加数据。
func (b *Builder) WriteString(s string) (int, error) {
b.copyCheck()
b.buf = append(b.buf, s...)
return len(s), nil
}- []byte的申请是成倍的,例如,初始大小为 0,当第一次写入大小为 10 byte 的字符串时,则会申请大小为 16 byte 的内存(恰好大于 10 byte 的 2 的指数),第二次写入 10 byte 时,内存不够,则申请 32 byte 的内存,第三次写入内存足够,则不申请新的,以此类推。 提供的String方法就是将[]byte转换为string类型,这里为了避免内存拷贝的问题,使用了强制转换来避免内存拷贝。
func (b *Builder) String() string {
return *(*string)(unsafe.Pointer(&b.buf))
}- bytes.Buffer:strings.Builder 和 bytes.Buffer 底层都是 []byte 数组,但 strings.Builder 性能比 bytes.Buffer 略快约 10% 。一个比较重要的区别在于,bytes.Buffer 转化为字符串时重新申请了一块空间,存放生成的字符串变量,而 strings.Builder 直接将底层的 []byte 转换成了字符串类型返回了回来。