
基础知识
INFO
不记笔记的后果就是每次都要从头学
激活函数
激活函数很多种,常用的比如sigmoid、ReLU和softplus,常用的是ReLU和softplus。激活函数是非线性的,可以使得原本线性的模型变得可以拟合非线性情况。
The Chain Rule
去复习你的高数
梯度下降法
用来算斜率和截距的。最无脑的方法是:不断改变值,然后把平方残差之和加起来,然后找到平方残差之和最小的组合,但是计算量太大了。梯度下降法在残差和很大时,采用大的变动;在残差和很小时采用小的变动。
最小二乘法直接求方程值为0的情况,但是方程不一定总能为0,而梯度下降法可以解决这个问题。
通过对方程求偏导的方式得到梯度,因此称为梯度下降法。一开始将两个变量的值随机取值,然后在梯度下降中用学习率(一个自定义常量)去规定每次更改的大小,不断迭代以减少平方残差之和。我们可以规定最小步长来结束梯度下降。
反向传播 BackPropagation
用于确定神经网络中的各参数,通过从后向前,利用梯度下降法求得各参数。 
交叉验证
涉及到测试集和训练集的选择。交叉验证会一次性使用所有的数据,将数据分为n块,用n-1块训练,1块测试。重复n次,使得每块都成为过测试块。最后比较正确率选择合适的模型进行拟合。
Ten-Fold Cross Validation
Leave One Out Cross Validation
混淆矩阵
通过混淆矩阵探查训练出的模型哪些判断错误,哪些判断正确,进而帮助选择合适的模型。
敏感性 & 特异性
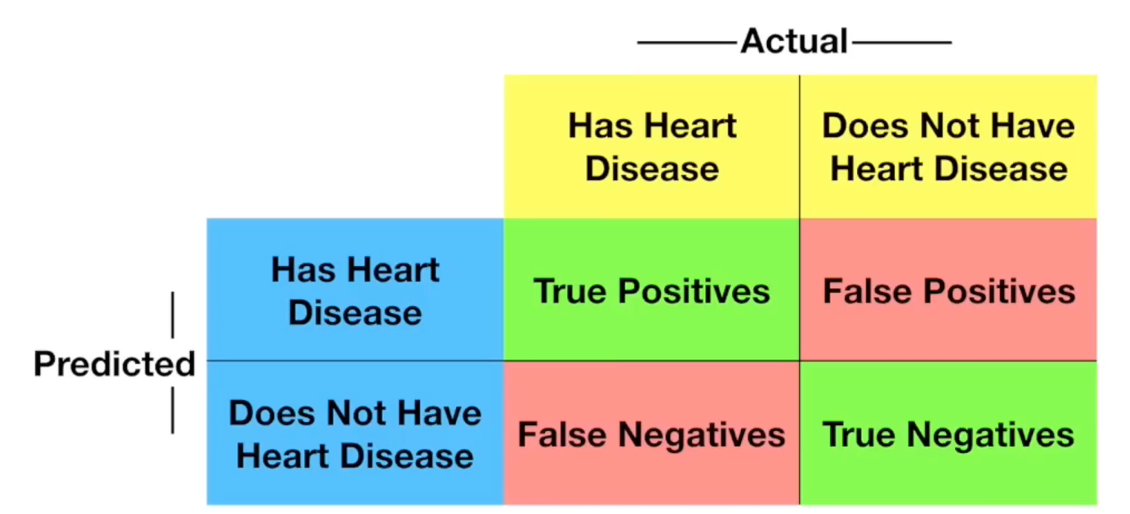 上面是混淆矩阵。
上面是混淆矩阵。 

ArgMax/SoftMax
因为最终输出结果范围不定,很难理解,因此通过ArgMax/SoftMax函数将最终输出结果进行限定。
ArgMax会将成功的输出结果直接变为1,其它为0。但是这样就不能用来优化神经网络中的权重和偏差了,也不能用来反向传播。
SoftMax一方面可以保留原始输出值的原始顺序或排名,另一方面可以让输出值都在0和1之间。可以解释为输出概率。
用ArgMax进行分类,用SoftMax进行训练。
交叉熵 Cross Entropy
我们将通过SoftMax函数处理过的预测概率输入交叉熵函数。交叉熵函数本身非常复杂,但是对于神经网络只需要用通用方程的简化形式。 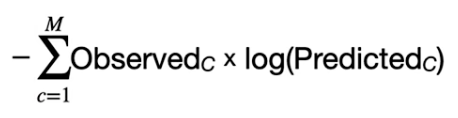
由于结果只有一个,所以除了结果的Observed都为0,实际上只有一项。即-log("p")
将每个可能性的交叉熵相加,得到的就是神经网络的总误差。
为什么不用平方残差和而是用交叉熵和呢?
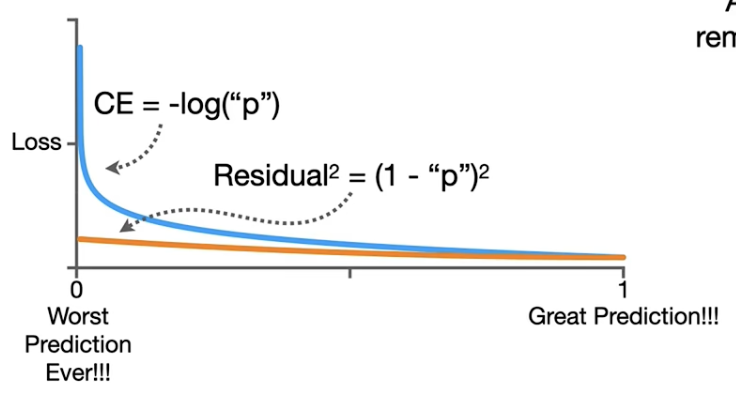
上图即可以看出,交叉熵函数的导数会在模型极差时变很大,这样在梯度下降时,可以向好的模型迈出更大的一步。
卷积神经网络 CNN
DANGER
怎么感觉年年都在学这个
图像不适合原本的神经网络,因此诞生了CNN。
- 减少了输入节点数
- 容忍图像的微小变化
- 能够发现同一图片中的相关性
CNN的滤波器/卷积核(Filter/Convolution)也是通过反向传播算出来的。卷积的出来的叫做特征图(Feature Map),然后特征图会过一遍ReLU函数,将负值清零,正值不变。然后经过池化再进入神经网络。
Max Pooling
选择区域内最大的值,即选择过滤器与输入图像匹配效果最好的点。
Average or Mean Pooling
将区域内的平均值算出来然后代替该区域。
Tensor 张量
神经网络中的张量与其它领域定义不一,张量是存储输入数据的方式。可以是一个值(零维张量),可以存储权重和偏置。数组为一维张量,矩阵为二维张量等等。张量的存在可以利用硬件(GPU,TPU)加速的优势。
RNN Recurrent Neural Networks 循环神经网络
之前的数据加权后与当前的数据结合用来预测未来的数据。每个输入都共享权重和偏差。 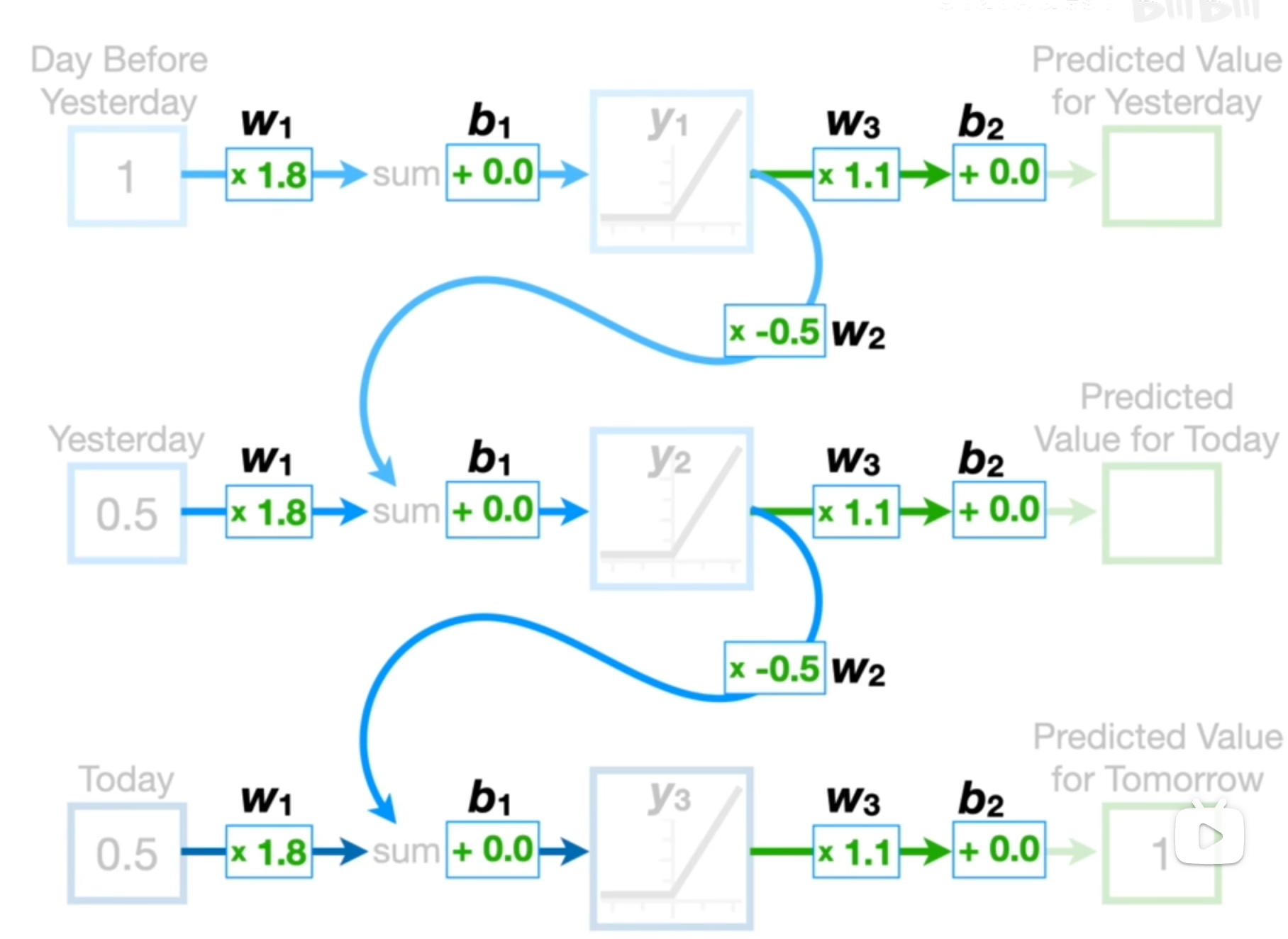
但是RNN存在梯度消失/爆炸问题,因为权重保持不变。因此RNN的使用并不频繁。 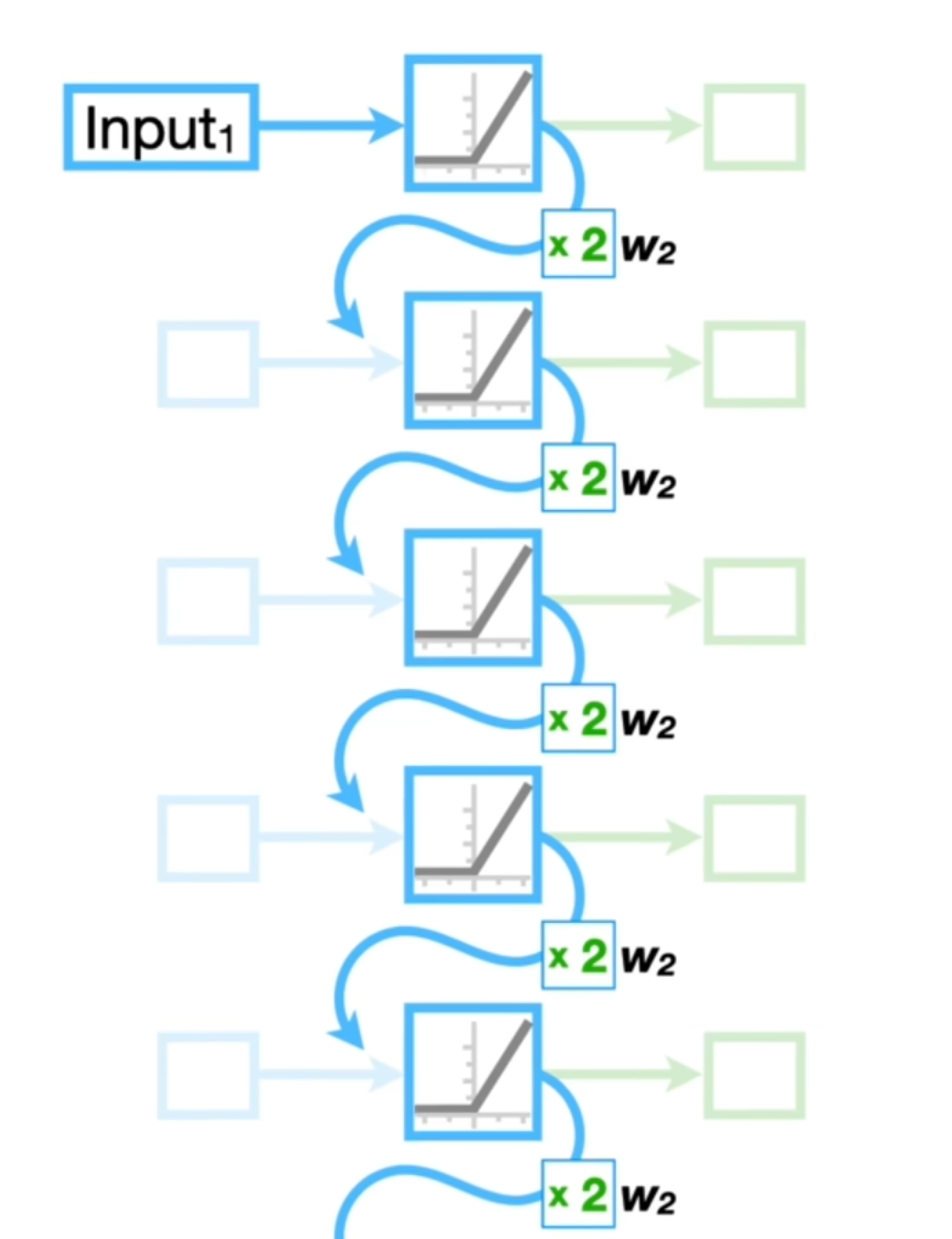
LSTM Long Short-term Memory
避免了RNN的梯度爆炸/消失问题。LSTM不再使用循环,而是使用两条独立路径来计算对未来产生影响:一条是long term memory,一条是short term memory。
LSTM使用Sigmoid和Tanh作为激发函数。 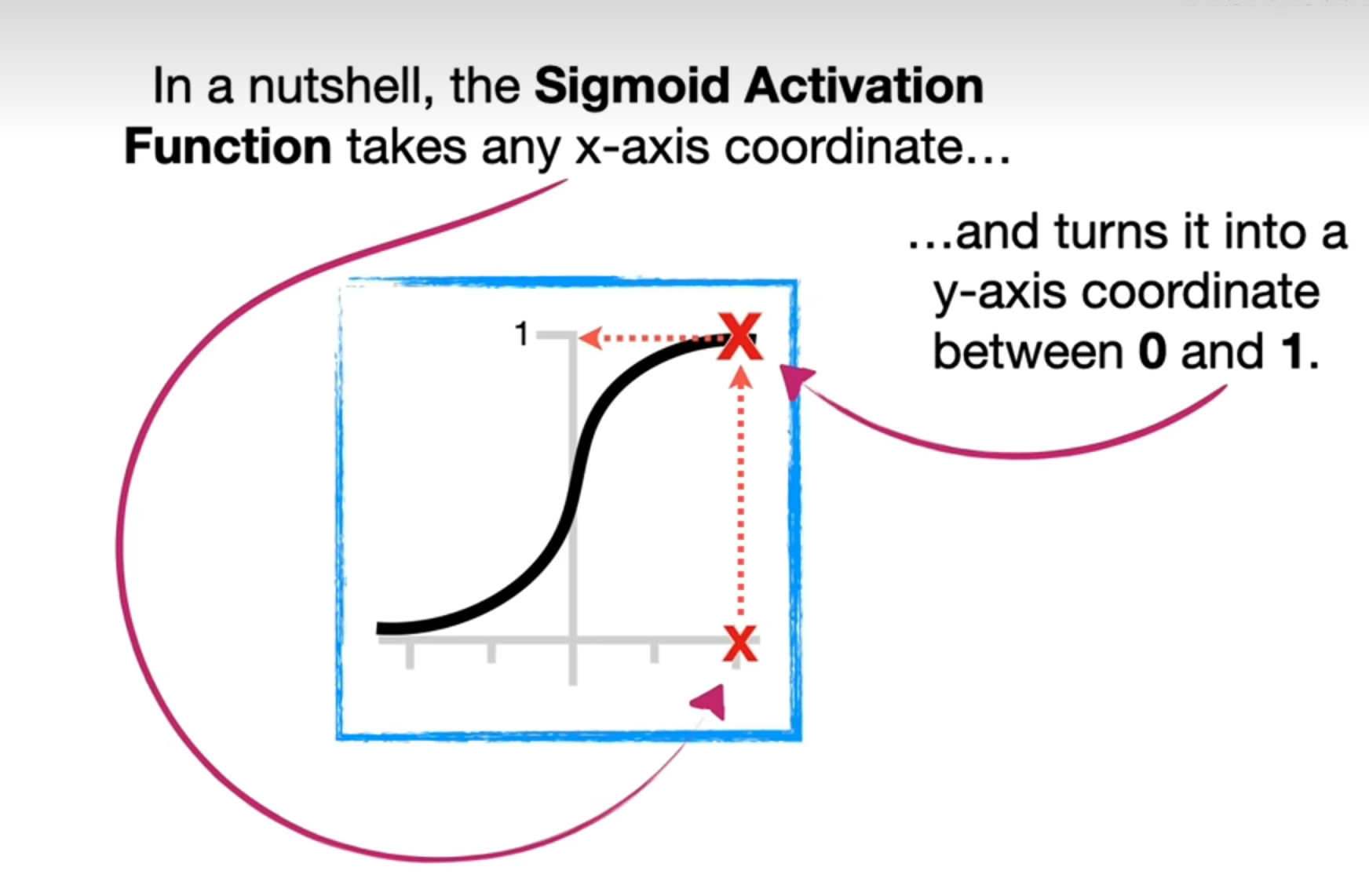
b站讲的好的 分为两个阶段,第一个阶段决定了长期记忆的百分比,也称为遗忘门。第二个阶段将短期记忆和输入结合。
词嵌入
将自然语言转换成神经网络能识别的元素。
seq2seq
从一个序列转换成另一个序列可以用到encoder-decoder模型来操作。注意,输入长度不统一,输出长度也不统一。
岭回归 Ridge Regression
最小二乘法(线性回归)容易导致过拟合情况,岭回归可以找到一条不符合训练数据的新路线。通过引入少量误差以适应数据,最终使得测试集误差减小,提供更好的长期预测。
具体操作是,以往仅需考虑残差平方和最小即可,现在考虑 (残差平方之和+λ*斜率平方)最小化 。斜率平方实际上是一个惩罚,λ决定了惩罚的力度。λ可以是任意值,λ越大,斜率越接近0。可以尝试一堆值,然后交叉验证,以确定哪个能导致最小的方差。
岭回归惩罚可以使最小二乘法的斜率明显下降,这样子坡度能下降。对离散数据也能有效。
综上,通过一些误差,尽管训练集不会那么完美,但是能避开过拟合,保证测试结果不会太离谱。